注意架构差异
举一个自旋锁的移植来说明这一点,假设在x86平台中有一个自旋锁实现如下所示:
#define barrier() __asm__ __volatile__("": : :"memory")
int CompareAndSwap(volatile int* ptr,
int old_value,
int new_value) {
int prev;
__asm__ __volatile__("lock; cmpxchgl %1,%2"
: "=a" (prev)
: "q" (new_value), "m" (*ptr), "0" (old_value)
: "memory");
return prev;
}
static void lock(int *l){
while(CompareAndSwap(l, 0, 1) != 0);
}
static void unlock(int volatile *l){
barrier();
*l = 0;
}
指令集差异
这是一个简化的自旋锁实现,在我们对CompareAndSwap这个函数进行移植时,我们首先关注到的是两个架构中指令集的差异。在这个实现中,通过内联汇编语法使用了x86架构下的cmpxchgl指令,但是在ARM架构下并没有与之完全一一对应的指令。
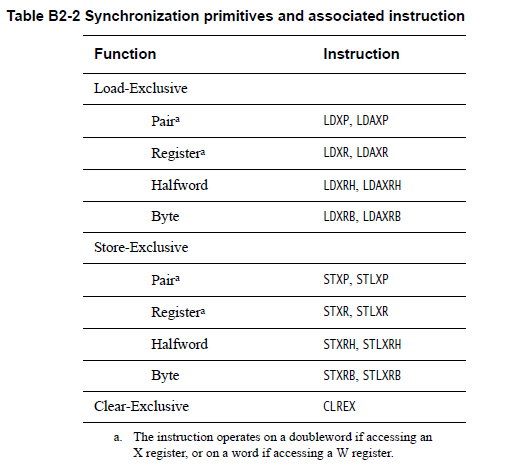
在ARM架构下,原子操作是通过exclusive指令对实现的,如下图所示(图片来自ARMv8体系结构参考手册):
所以我们使用exclusive指令对来实现这个CompareAndSwap函数,如下所示:
int CompareAndSwap(volatile int* ptr,
int old_value,
int new_value) {
int prev;
int temp;
__asm____volatile__ (
"0: \n\t"
"ldxr %w[prev], %[ptr] \n\t"
"cmp %w[prev], %w[old_value] \n\t"
"bne 1f \n\t"
"stxr %w[temp], %w[new_value], %[ptr] \n\t"
"cbnz %w[temp], 0b \n\t"
"1: \n\t"
: [prev]"=&r" (prev),
[temp]"=&r" (temp),
[ptr]"+Q" (*ptr)
: [old_value]"IJr" (old_value),
[new_value]"r" (new_value)
: "cc", "memory"
);
return prev;
}
内存序差异
在如上述所示替换了CompareAndSwap函数之后,发现自旋锁并没有按预期工作,其主要是x86架构和ARM中的内存序差异导致的。
修改前:
static void lock(int *l){
while(CompareAndSwap(l, 0, 1) != 0);
}
static void unlock(int volatile *l){
barrier();
*l = 0;
}
如表1所述,在ARM架构下允许原子操作和内存读写之间的乱序,导致了上述代码中lock函数之后的内存访问可能被乱序到lock中的原子操作获取到锁之前执行,进而导致了非预期程序行为。
另一方面,在释放锁的时候,原代码中使用了一个编译型内存屏障,但是在ARM更宽松的内存序模型下不足以保证正确,需要改为CPU级的内存屏障,
修改后代码如下所示:
#define smp_mb() asm volatile("dmb ish" ::: "memory")
static void lock(int *l){
while(CompareAndSwap(l, 0, 1) != 0);
smp_mb();
}
static void unlock(int volatile *l){
smp_mb();
*l = 0;
}
至此该自旋锁在功能上的移植就完成了,经过验证这个实现可以按预期工作。实际上,根据尽可能使用acquire和release语义进行同步中所述,我们可以通过半屏障来进一步优化这个锁的实现,提升锁的性能。在获取锁的时候只需要acquire语义,而释放锁的时候只需要release语义,从而去掉上面所使用的CPU级的全屏障。最终移植到ARM架构下的实现如下所示:
int CompareAndSwap(volatile int* ptr,
int old_value,
int new_value) {
int prev;
int temp;
__asm____volatile__ (
"0: \n\t"
"ldaxr %w[prev], %[ptr] \n\t"
"cmp %w[prev], %w[old_value] \n\t"
"bne 1f \n\t"
"stxr %w[temp], %w[new_value], %[ptr] \n\t"
"cbnz %w[temp], 0b \n\t"
"1: \n\t"
: [prev]"=&r" (prev),
[temp]"=&r" (temp),
[ptr]"+Q" (*ptr)
: [old_value]"IJr" (old_value),
[new_value]"r" (new_value)
: "cc", "memory"
);
return prev;
}
static void lock(int *l) {
while(CompareAndSwap(l, 0, 1) != 0);
}
static void unlock(int volatile *l)
{
int zero = 0;
__atomic_store(l, &zero, __ATOMIC_RELEASE);
}
父主题: 锁的移植