QE性能优化
QE(Quantum-espresso)以第一性原理密度泛函理论为基础,其主要包括两大模块PWscf和CPMD。
QE更多信息请参考官网:http://www.quantum-espresso.org/
自2016年以来,QE开发了一个用CUDA Fortran编写的GPU加速版本,该版本是由NVIDIA和QE开发人员联合开发的。它是用于GPU的CUDA Fortran和用于CPU的MPI + OpenMP的混合实现。目前最新版本v7.0. QE-GPU被认为是稳定的,也会定期进行更新。以下为GPU加速的模块列表。

QE最主要的同时使用最广泛的包是PWscf。该软件包在平面波的基础上求解K-S方程,并迭代直到形成自洽场。PWscf代表平面波自洽场。它是一种迭代方法,用于解决了相互依赖的多个方程。从一个非常简化的角度来看,可以把这个过程看作是解第1个方程,然后是解第2个方程,最后是解第3个方程。然后用第3次的解再次求解第1个方程,但比第1次的求解结果更准确,一开始,计算的结果将波动很大,但我们可以持续迭代这个循环,直到计算的结果开始收敛。这就是所谓的自洽。在每个循环中,都有多个步骤和问题需要解决,这些步骤和问题通常涉及许多线性代数和快速傅里叶变换。整个算法流程如下图所示。
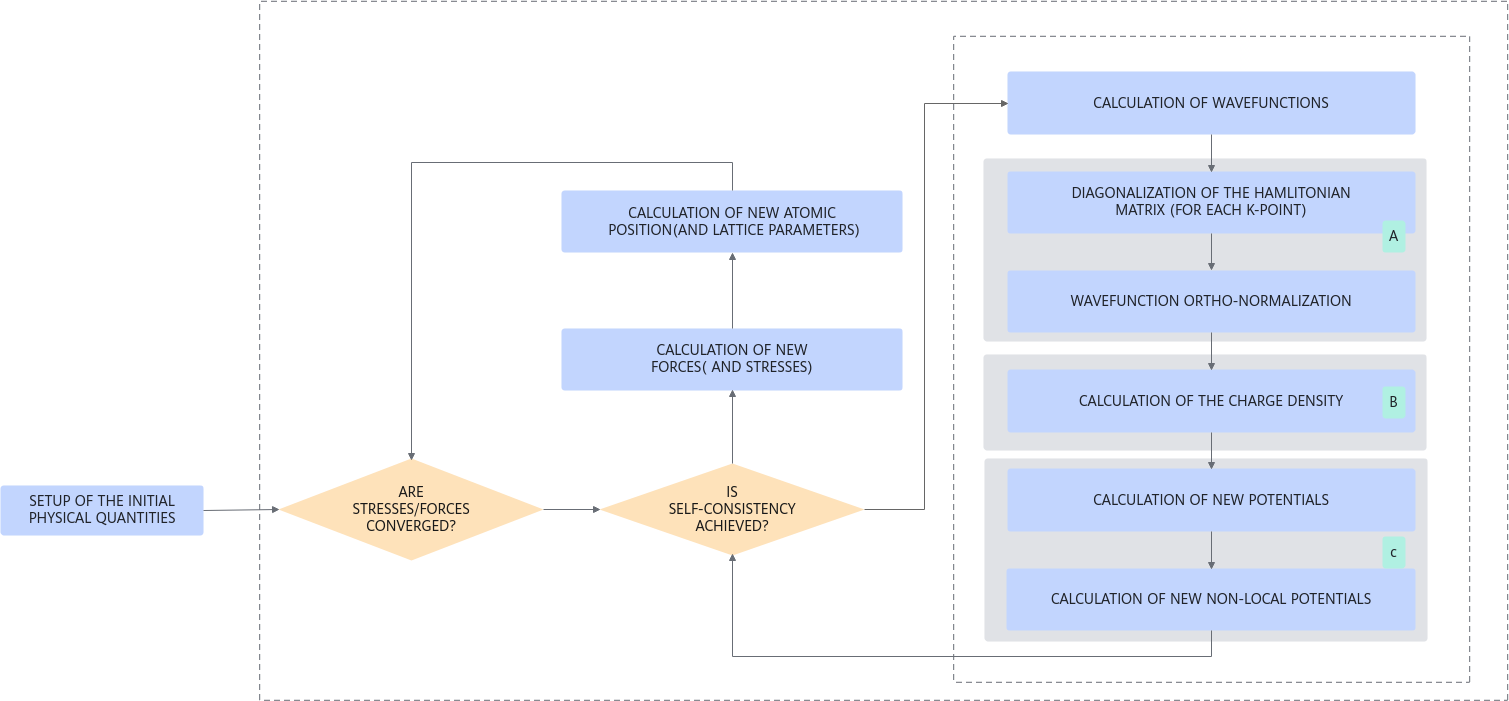
带有绿色阴影方块的步骤中的主要计算模式:
A. 3D-FFT +矩阵运算[f1] +Lapack运算
B. 3D-FFT +矩阵运算
C. 3D-FFT
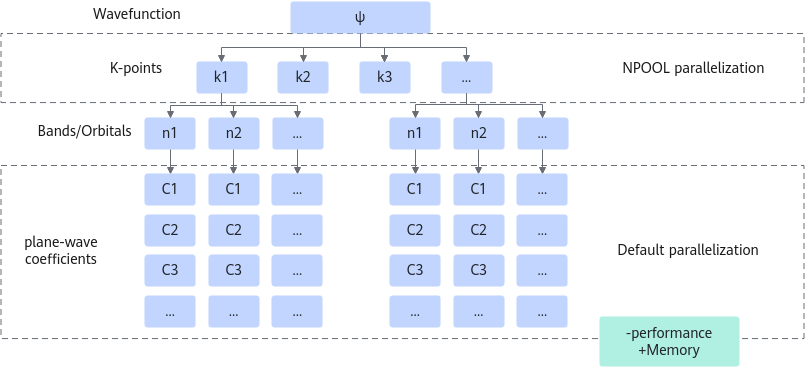
QE GPU版本中有两个主要的并行优化可用。因为它们可以在运行时进行选择,可以提供显著的性能增益。求解QM方程的方式提供了一些并行代码的方法,这些方法如下所示。
从上到下,代码的目标是计算波函数(△),因为它需要解决一组称为k点的独立子问题。然后,对于每个k点,每个频带上的环路,我们有一组PW系数。QE在所有MPI进程之间分割所有系数。这具有分割内存使用的优点,但作为一种权衡,它在这些MPI进程之间引起了大量的通信。因此,当有足够的内存可用时,最好使用通过划分K点池的策略。k点级别是一个令人尴尬的并行级别,比如我们可以为每个GPU分配一个k点,并且这些GPU之间根本没有通信。
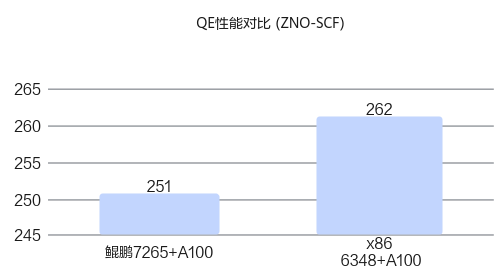
接下来基于ZNO-SCF算例进行测试,测试软件栈如下所示。
软件栈 |
X86 6348(2P) A100*2 |
Kunpeng 920-7265(2P) A100*2 |
|---|---|---|
|
Kylin V10 |
Kylin V10 |
Memory |
16*16GB |
16*16GB |
MPI |
英伟达GPU版openMPI4 |
英伟达GPU版openMPI4 |
Compiler |
Intel 2021 |
鲲鹏GCC 9.3.1 |
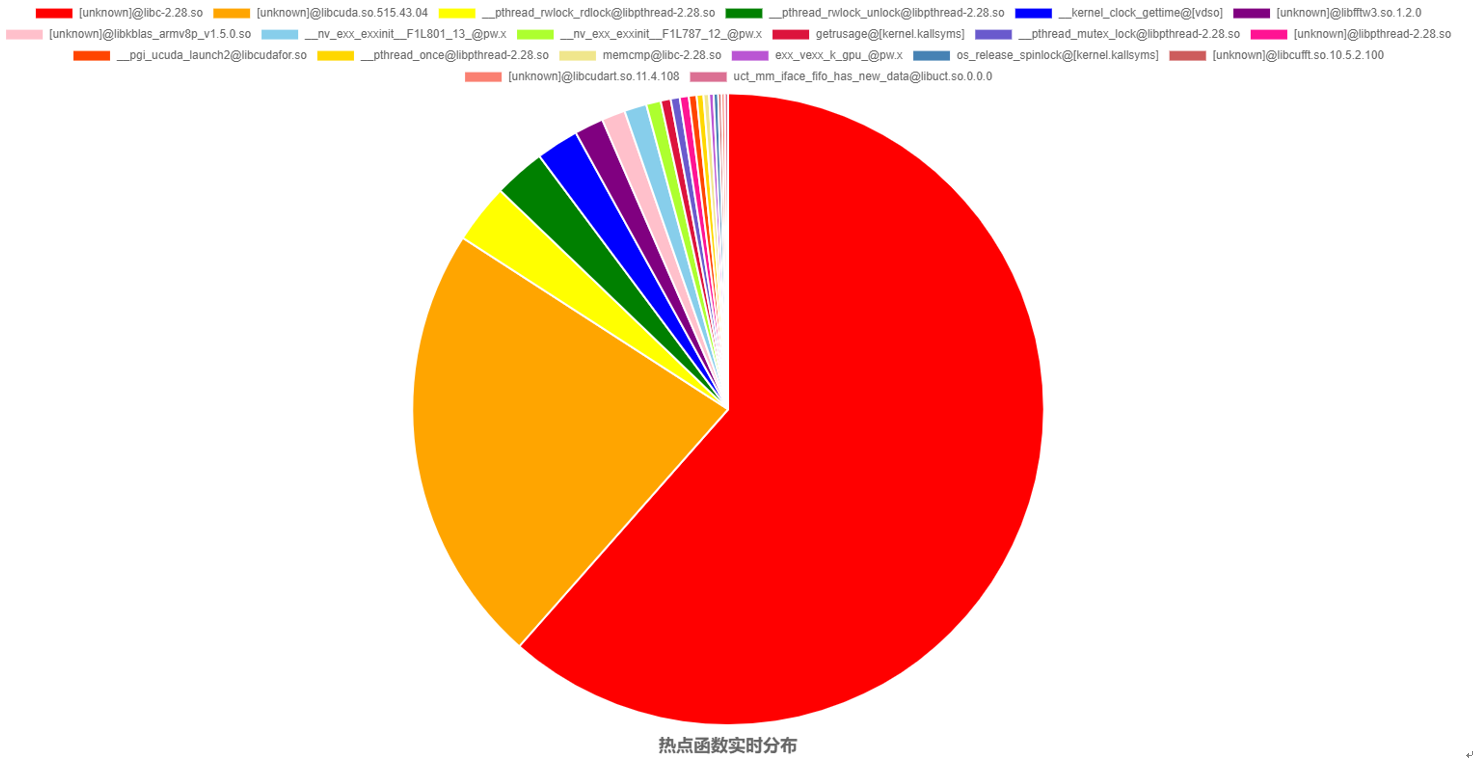
在鲲鹏上采集的热点函数分布如下所示,可以看到GPU占比非常高(80%以上),比较适合拿来优化。
先用NSYS将GPU上面的代码进行性能采集,如下所示:
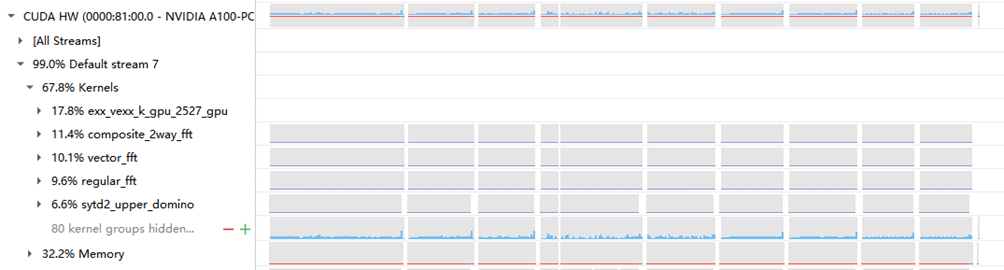
从热点情况来看,以GPU的热点为主,占据热点的50%~70%;但是GPU内的核函数热点较分散,主要耗时的核函数均提示利用率较低且网格划分过小。
使用命令nvidia-smi查看GPU卡利用率,发现双卡的利用率看起来也不高,说明还有比较大的优化空间。
GPU编译选项参数优化
QE主要是Fortran语言实现为主,基于GPU编译参数优化的编译选项进行测试,发现如下选项有小幅提升。
编译选项 |
优化原理 |
|---|---|
-O 0 1 2 3 4 |
代码优化级别,这里选择O4 |
-Mipa |
进行过程分析优化 |
-Munroll |
循环展开 |
-Mvect |
自动向量化 |
-use_fast_math |
使能向量化、cache对齐、FTZ等内容 |
--fma |
是否使能乘加合并计算,这里设为--fma=true |
MPS优化
通过性能特征分析发现GPU利用率比较低,GPU的功耗也没有达到最高,因此考虑使用MPS服务,多进程服务是一种使多个 CPU 进程提交的计算内核能够在同一GPU上同时执行的工具。这种重叠可能实现更彻底的资源使用和更好的总体吞吐量。而且测试发现,当进程数为8时K-S方程的负载均衡最佳。
跨卡优化
默认情况下两张卡都共用一个CPU,因此会抢占PCIE总线,造成不必要的资源冲突,因此需要固定CPU各使用一张卡,如下所示:
mpirun --allow-run-as-root -np 8 -x CUDA_VISIBLE_DEVICES=0,2 -x OMP_NUM_THREADS=1
pw.x -nk 8 -input scf.in
kernel代码优化
针对热点Kernel代码vexx_k_gpu,根据特征分析发现存在线程发散和Block数目过少现象,因此将循环内的判断条件外提,并且适当增加Block数目,如下所示:
优化前:
all_start_tmp=all_start(wegrp) DO jbnd=jstart, jend !$cuf kernel do (1) DO ir = 1, nrxxs IF (noncolin) THEN result_nc_d(ir,1,ii) = result_nc_d(ir,1,ii) & + vc(ir,jbnd-jstart+1) * exxbuff(ir,jbnd-all_start_tmp+iexx_start,ikq) result_nc_d(ir,2,ii) = result_nc_d(ir,2,ii) & + vc(ir,jbnd-jstart+1) * exxbuff(ir+nrxxs,jbnd-all_start_tmp+iexx_start,ikq) ELSE result_d(ir,ii) = result_d(ir,ii) & + vc(ir,jbnd-jstart+1)*exxbuff(ir,jbnd-all_start_tmp+iexx_start,ikq) ENDIF ENDDO ENDDO
优化后:
all_start_tmp=all_start(wegrp) IF (noncolin) THEN DO jbnd=jstart, jend !$cuf kernel do <<<16,*,stream=cudaGetStreamDefault()>>> DO ir = 1, nrxxs result_nc_d(ir,1,ii) = result_nc_d(ir,1,ii) & + vc(ir,jbnd-jstart+1) * exxbuff(ir,jbnd-all_start_tmp+iexx_start,ikq) result_nc_d(ir,2,ii) = result_nc_d(ir,2,ii) & + vc(ir,jbnd-jstart+1) * exxbuff(ir+nrxxs,jbnd-all_start_tmp+iexx_start,ikq) ENDDO ENDDO ELSE DO jbnd=jstart, jend !$cuf kernel do <<<16,*,stream=cudaGetStreamDefault()>>> DO ir = 1, nrxxs result_d(ir,ii) = result_d(ir,ii) & + vc(ir,jbnd-jstart+1)*exxbuff(ir,jbnd-all_start_tmp+iexx_start,ikq) ENDDO ENDDO ENDIF
经过上述优化,鲲鹏平台性能实现倍增,持平C1下一代芯片。