应用Core Bound占比较高
现象
应用运行时,如发现应用Core Bound占比较高,可通过调整运算操作或变量精度,减少资源消耗。
调优思路
使用鲲鹏DevKit系统性能分析的HPC应用分析发现问题点,对运算操作及变量的精度进行微调,以便达到减少资源消耗的目的。
操作步骤
- 准备示例源码core_bound.c并进行编译。
gcc core_bound.c -O3 -o core_bound -fopenmp -lm
- 使用鲲鹏DevKit系统性能分析执行HPC应用分析任务。
表1 任务配置参数说明 参数
说明
分析对象
应用
应用路径
输入程序所在的绝对路径,例如本示例将代码样例放在服务器“/opt/testdemo/core_bound”路径下。
分析类型
HPC应用分析
采集模式
OpenMP模式;本示例主要是对OMP的应用进行分析。
分析模式
统计分析
采样模式
Summary模式
采样时长
默认
- 查看任务结果。
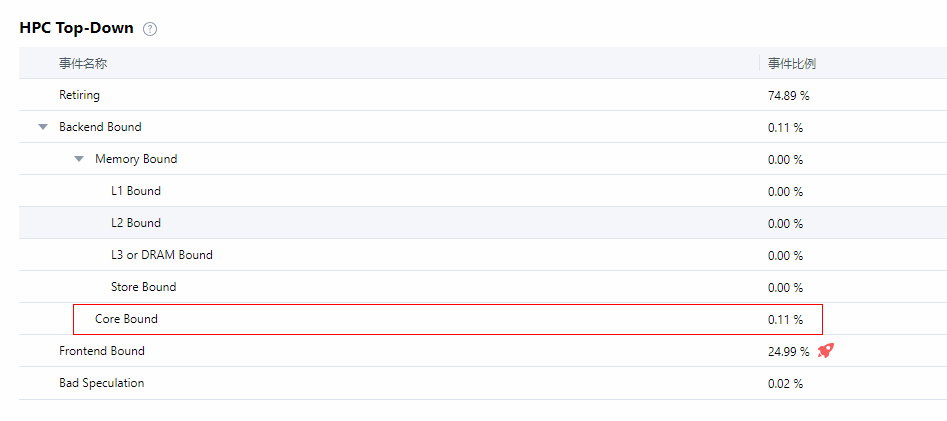
观察Top-Down各项指标,发现其中Core Bound占比为87.4%,远高于其他指标比率。
图1 HPC Top-Down
- 进一步观察热点函数,同时对源码进行分析。
热点函数CoreBoundBench_OPT存在sdiv操作,导致core bound占比较高。
void CoreBoundBench() { int i; __asm__ volatile(".rept 3 \n\t" "nop \n\t" ".endr"); __asm__ volatile("mov x12, 2"); for (i = 0; i < INTRA_LOOP_SIZE; i++) { __asm__ volatile("sdiv x11, x11, x12"); } } - 源码优化。
在源码内对关键函数CoreBoundBench_OPT进行修改,利用移位操作代替除法操作,从而减小core bound占比。
void CoreBoundBench_OPT() { int i; __asm__ volatile(".rept 3 \n\t" "nop \n\t" ".endr"); for (i = 0; i < INTRA_LOOP_SIZE; i++) { __asm__ volatile("lsr x11, x11, #1"); } } - 将修改后源码重新编译。
使用1中的命令重新编译应用并使用工具进行分析。
优化效果
优化后,应用执行时间缩短,同时Core Bound占比由87.4%下降为0.11%。