分析top热点函数
进入系统性能分析,采用热点函数分析,确定哪些热点函数存在性能瓶颈。
IDR指令比例高
开启CPU Prefetching。

CPU将内存中的数据读到CPU的高速缓存Cache时,除了读取本次要访问的数据,还会预取本次数据的周边数据到Cache里面,如果预取的数据是下次要访问的数据,那么性能会提升;如果预取的数据不是下次要取的数据,那么会浪费内存带宽。
对于数据比较集中的场景,预取的命中率高,适合打开CPU预取;若数据不集中,预取命中率低,则浪费内存带宽。
内联函数
频繁调用的小函数优化成内联函数,内联函数是典型的空间换时间的优化方法。
参考链接:https://www.hikunpeng.com/document/detail/zh/perftuning/tuningtip/kunpengtuning_12_0085.html
NEON指令加速
采用NEON指令向量化优化。
参考链接:https://www.hikunpeng.com/document/detail/zh/perftuning/tuningtip/kunpengtuning_12_0053.html
循环优化
循环优化是对程序中使用到的循环部分进行代码优化,合理的优化可以充分利用处理器的计算单元,提升指令流水线的调度效率,也可以提升Cache命中率。循环的方法有很多,如循环展开、循环融合、循环分离、循环交换和循环平铺。
- 循环展开
循环展开是将循环体重复多次来减少循环,通常使用在小循环中。可以利用Kunpeng处理器具有多个指令执行单元的特点,增加计算密度,提升指令流水线的调度效率。
小循环内部没有判断逻辑,收益较高;大循环展开有可能会引起通用寄存器的溢出,降低性能(寄存器重命名/外溢至内存);内部有判断逻辑可能会增加分支预测的开销,需要具体情况具体分析。
- 循环融合
循环融合是将相邻或紧密间隔的循环融合在一起,减少对循环变量的操作。迭代变量在循环体内被使用,可以提高Cache的使用率。合并小循环后也有利于增加TaiShan处理器乱序执行的机会,提升指令流水线的调度效率。
- 循环分离
- 循环交换
- 循环平铺
循环平铺是指将一个循环拆分成一组嵌套循环,每个内部循环负责一个小数据块,以便最大化利用Cache中的现有数据,提高Cache命中率,通常针对比较大的数据集。
参考链接:https://www.hikunpeng.com/document/detail/zh/perftuning/tuningtip/kunpengtuning_12_0083.html
分支优化
- 分支预测优化
- 优化逻辑表达式
表1 逻辑表达式优化方案 场景
方案
if ((i < 4) || (i & 1)) { ... }
如果i更可能为1的话,更好的方式改成位操作的性能更好,if ((i & 1) || (i < 4)) { ... }。
if ((strlen(p) > 4) && (*p == 'y')) { ... }
如果p为y的概率更低,strlen函数的代价更大,更好的方式为if ((*p == 'y') && (strlen(p) > 4)) { ... }。
if (a <= max && a >= min && b <= max && b >= min)
如果大部分的数据都不在这个范围内,修改成下面这种方式if (a > max || a < min || b > max || b < min)。
- 多分支使用switch替换if-else
Cache优化
- cacheline对齐
参考链接:https://www.hikunpeng.com/document/detail/zh/perftuning/tuningtip/kunpengtuning_12_0052.html
- 消除伪共享
伪共享是指多核的多个私有变量位于同一个cacheline内,由于每个核修改变量时,会将其它核的整个cacheline无效掉,这样就会造成该cacheline在不同的核频繁迁移。这种现象类似共享变量的读写,但又不是真正的共享变量,故称伪共享。如图 伪共享所示。
CPU0与CPU1的私有变量刚好位于同一个cacheline内(私有变量分别对应红色块与蓝色块),CPU0修改其私有变量,会将整个cacheline无效,CPU1要访问其私有变量又需要重新从内存中读取,效率降低。
优化方案:
- OpenMP代码中使用reduction子句代替直接写入共享变量(循环过程中写入线程私有变量)。
- 线程私有的变量按照cacheline大小对齐(线程栈上的变量除外)。
- 使用线程私有变量(如GCC支持_thread,C11支持_Thread_local关键字)。
- 数据重排
数据重排是指物理上不连续的热点数据变成连续的数据,使得CPU可以按cacheline访问,提升Cache命中率。例如矩阵乘法,假设矩阵按行储存,则读取矩阵B的列元素不连续,Cache命中率低。(为了方便理解,下图假设B矩阵的行/列元素总大小与Cache块大小一致)
图2 矩阵乘法1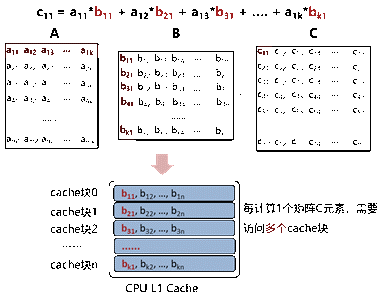
通过对矩阵B重排后,提升了Cache命中率,可以从L1 Cache中连续读取列元素。
图3 矩阵乘法2
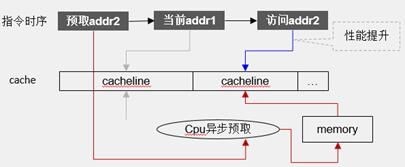
- 使用软件预取
软件预取是指通过PRFM指令提前将后面要使用的数据加载到Cache中,避免使用时再读取数据增加Cache Miss的内存访问延迟。如图4所示,提前预取addr2的数据,执行addr1完成,addr2的数据已经准备好。
GCC中可以使用_builtin_prefetch()函数,函数原型为_builtin_prefetch(const void addr, int rw, int locality),其中add为要预取的地址,rw预取addr所在cacheline,接下来是要做什么操作(读还是写,取值可为0/1,默认值为0,0表示读,1表示写),locality为预取之后访问此cacheline的频率(取值可为0/1/2/3,0表示只访问一次,该cacheline不应该驻留;3表示该条cacheline将来会被较为频繁地访问,应尽量驻留在所有level的Cache中)。

结构体优化
- 字节对齐
首先解释一下对齐的概念,例如总线的数据宽度为64bit(8byte对齐),burst size=64bit,burst length=4,如果要往地址0xf0002000写入32byte,只要一次传输就可以完成。如果要往0xf0002001写入32byte,就要拆分成2次非对齐传输了,显然传输效率比一次传输要差。
图5 字节对齐
虽然鲲鹏CPU目前支持非对齐访问,但如果对要频繁访问的结构体使用了非字节对齐,会造成读写效率低下。不同Load/Store指令对对齐访问的要求不同。GCC中使用字节对齐的例子如下,默认为8字节对齐。
struct person1{ char *name; int age; char score; int id; }__attribute__((packed)); struct person2{ char *name; int age; char score; int id; }__attribute__((aligned(4)));图6 GCC字节对齐
保持结构体字节对齐主要是使得CPU从内存读取数据到Cache的延迟降低。
- 调整成员顺序
有时对于一个较大的结构体,如果某两个结构体成员间隔较大,跨越了2个cacheline,刚好某个热点函数需要频繁访问这两个成员,可能引起较大的cache Miss(一个成员的修改可能导致另一个成员所在的cacheline被替换出去)。可以将两个成员放入一个cacheline内,提升Cache的利用率。
减少不必要的Barrier
现代CPU为了提升流水线的执行效率,一般都实现了乱序执行的功能,意味着代码的指令顺序与指令实际执行顺序可能不一样,特别是没有寄存器依赖的两条指令,执行顺序无法确定。但有些场景下,希望这两条指令是保序的,比如往某个内存地址写入一个值后,需要等到写入完成后(写入内存是需要时间的),再往某个外设寄存器中写入数据,因为这个寄存器地址与内存地址没有数据依赖,CPU无法保证执行顺序,所以提供了Barrier指令供程序员手动进行保序。

ARMv8提供3条Barrier指令:DMB、DSB、ISB
DMB:数据存储器隔离。
DSB:数据同步隔离。
ISB:指令同步隔离,比DMB严格。
DMB、DSB、ISB执行代价依次递增,从性能角度考虑,能不用Barrier的地方尽量不用,能用DMB的,不要用DSB/ISB。另外,需要注意ARMv8增加了Load acquire/Store release指令,隐含了Barrier操作,具体参见章节。
访存优化
- 减少不必要的内存读写和分配。
如图8所示,第二个函数,指示了编译器,hash变量是临时变量,中间不需要保存到栈中,到计算结束的时候直接返回即可。减少了不必要的内存读写。
另外,内存分配是一项开销较大的操作,对于频繁使用的内存,可以考虑在初始化时创建内存池,后续直接从内存池获取内存块。特别要注意避免在循环中不必要的分配内存。
- 不要频繁使用指针获取数据,优先局部栈变量。
图9 优先局部栈变量

- 合理使用全部变量。
在编程中使用全部变量的,编译器优化后进入某函数栈,加载至对应代码块时编译器不会为全局变量分配寄存器;而使用局部变量可以在编译器优化时编译出寄存器级别操作,减少多余的Load操作。
优化方案:
- 非必要场景,建议使用局部变量;
- 若涉及全局变量需要被多个函数读取,而不是修改的场景,可以将全局变量作为形参的形式传入,并添加const关键字,避免在函数调用过程中全局变量被修改;
- 若全局变量要被别的模块调用时,建议get/set形式封装,避免直接使用全局变量。

多核优化
- 锁优化
LL/SC(Load-link/Store-condition)原子指令需要把共享变量先load到本核所在的L1 Cache中进行修改,在锁竞争少的情况下性能较好,但在锁竞争激烈时会导致系统性能下降严重。ARMv8.1规范中引入了新的原子操作指令扩展LSE(Large System Extensions),将计算操作放到L3 Cache去做,增大数据共享范围,减少Cache一致性耗时,在锁竞争激烈时可以提升锁的性能。
在多核、原子核争抢严重的情况下,建议在GCC编译选项中添加LSE相关选项,减缓缩竞争。
图10 LL/SC指令(ldaxr&stlxr) 图11 LSE指令(ldaddal)
图11 LSE指令(ldaddal)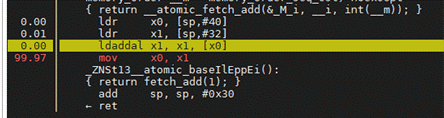
优化方案:
GCC 6.0以上版本支持(建议使用GCC 7.3.0以上版本),可以在编译选项中增加“-march=armv8-a+lse”、“-march=armv8.1-a”或者“-march=armv8.2-a”选项。
- 避免不必要的Barrier
由于ARMv8提供Load acquire/Store release指令LDAR/STLR,隐含了Barrier操作,在实现原子操作时,要避免不必要的Barrier。
图12 one-way Barrier 图13 Load acquire/Store release指令
图13 Load acquire/Store release指令
- 减少跨NUMA调用
鲲鹏处理器为乐高架构,每个处理器Socket内部拥有两个NUMA Node。线程/进程实际运行所在的物理核与内存NUMA Node位置关系,会带来访存路径时延的差异,本地访问性能最佳,本Socket内跨一次NUMA次之,跨Socket访问性能最不理想。
图14 NUMA节点配置
优化方案:
- 避免线程在运行过程中迁移:使用OpenMP时,通过配置环境变量OMP_PROC_BIND=true及OMP_PLACES指定线程要绑定的CPU核。
图15 线程绑核

- 用numactl工具、taskset、cgroup/cpuset工具绑定进程/线程的位置关系。
图16 NUMA绑核

- 避免线程在运行过程中迁移:使用OpenMP时,通过配置环境变量OMP_PROC_BIND=true及OMP_PLACES指定线程要绑定的CPU核。
