OmniData算子下推组网规划
建议采用存算分离组网,即存储节点和计算节点分离,以便更好地利用OmniData算子下推特性实现存算协同,将算子下推到存储节点进行就近计算,进而提升大数据计算性能。如果OmniData算子下推和OmniOperator算子加速两个特性叠加使用,则也建议参考本节组网要求进行规划。
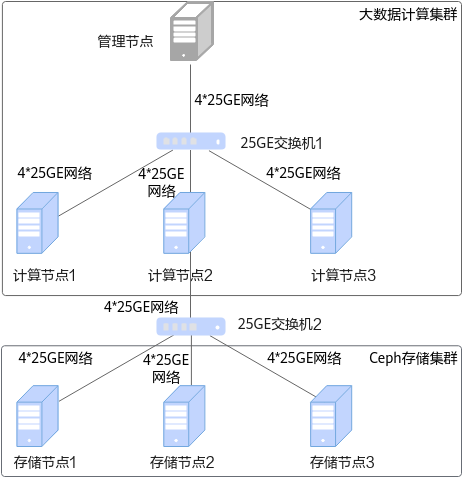
本文规划的环境由7台服务器组成,以此举例,使用存算分离的组网,分别是管理节点(1台)、计算节点(3台)、存储节点(3台)。以存储节点为Ceph进行举例说明,其中:
- 管理节点为server1,用于管理任务。
- 计算节点为agent1、agent2和agent3,用于运行大数据查询引擎服务。
- 存储节点为ceph1、ceph2和ceph3,用于运行OmniData算子下推服务。

OmniData算子下推提供算子下推(算子卸载)的执行能力,接收Host Runtime下推下来的任务,因此OmniData算子下推部署节点即为卸载节点。本文主机架构为CPU架构,OmniData算子下推部署在存储节点,即文中卸载节点为存储节点。
一台服务器可以同时充当管理节点、计算节点和存储节点(如果是单机安装模式,后续文章中提到的在管理节点/计算节点/存储节点(卸载节点)上执行的操作,均需要在一个节点上执行),组网规划如图1所示。
父主题: 组网规划