分类回归
GBDT算法调优
不同的应用场景对应着不同的样本空间,因此同一种算法在不同场景即使采用相同的参数,其性能表现也是有所不同的,主要体现在预测的精度和算法收敛速度,但是可以调节模型的一些参数来加快模型的收敛,提高模型的精度,从而提升算法的性能,以GBDT算法为例,简单介绍一下各个参数对模型的性能影响。
参数 |
说明 |
建议 |
|---|---|---|
numPartitions |
Spark分区数量,分区越多意味着任务数太多,每次调度耗时会增加,分区太少,会导致一些节点没有分配到任务,并且会使每个分区处理的数据量增大,从而使每个agent节点内存提高。 |
在0.5~1.5倍的总核数(executor_cores与num_executor乘积)进行网格搜索,建议使用1倍总核数。 |
maxIter |
最大迭代次数,或者子树的最大个数,太小容易欠拟合,太大容易过拟合,并且使模型收敛速度变慢。 |
在80~120范围内进行搜参,建议使用缺省值100。 |
stepSize |
学习率,即每次迭代子树权重更新幅度,太大会导致收敛震荡,无法收敛,太小收敛较慢,容易陷入局部最优。 |
在0~1范围内进行搜参,建议使用0.1。 |
maxDepth |
每棵子树的最大树深,取决于样本的特征的多少,即使特征多也不要使用太大,影响延缓收敛速度,并且容易过拟合。 |
常用的取值范围3~100,建议使用5。 |
maxBins |
每棵子树划分考虑的最大特征数,取决于总的特征数N,太大影响子树生成时间。 |
建议使用 |
doUseAcc |
特征并行训练模式开关。设置值包括true(特征并行)和false(样本并行)。 |
Boolean,缺省值为true。 |
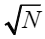
Random Forest算法调优
简单介绍Random Forest算法各个参数对模型的性能影响。
参数 |
说明 |
建议 |
|---|---|---|
genericPt |
数据读取时的重分区数量,分区越多意味着任务数太多,每次调度耗时会增加,分区太少,会导致一些节点没有分配到任务,并且会使每个分区处理的数据量增大,从而使每个agent节点内存提高。 |
在1~2倍的总核数(executor_cores与num_executor乘积)进行网格搜索,建议使用1倍总核数。 |
numCopiesInput |
训练数据的副本数量,优化算法新增参数,通过spark.boostkit.ml.rf.numTrainingDataCopies参数设置。与并行度和内存占用有关,调大此参数会提升并行度、增大内存开销。 |
默认取值为1。 |
pt |
优化算法训练阶段会用到的分区数,通过spark.boostkit.ml.rf.numPartsPerTrainingDataCopy参数设置。 |
建议取值为总核数/numcopies,向下取整。 |
featuresType |
训练样本数据中特征的存储格式,优化算法新增参数,通过spark.boostkit.ml.rf.binnedFeaturesDataType参数设置。枚举类型,取值为array或fasthashmap,缺省值为array。 |
维度大于5000时建议设置为fasthashmap;维度小于5000时建议设置为array。 |
broadcastVariables |
是否广播具有较大存储空间的变量,优化算法新增参数,通过spark.boostkit.ml.rf.broadcastVariables参数设置,缺省值为false。 |
维度大于10000时建议设置为true。 |
maxDepth |
每棵子树的最大树深,取决于样本的特征的多少,即使特征多也不要使用太大,影响延缓收敛速度,并且容易过拟合。 |
常用的取值范围3~100,建议取值范围11-15。 |
maxBins |
每棵子树划分考虑的最大特征数,值越大越接近精确求解,但太大影响子树生成时间。 |
建议取值为128。 |
maxMemoryInMB |
存储统计信息的内存最大值。增加此参数允许更少的数据遍历,可以提升训练速度;但增加此参数也会增加每次迭代的通信开销。 |
建议取值为2048或4096, 对于维度大的数据集可以考虑增加此参数,如设置为10240。 |
SVM算法调优
简单介绍SVM算法各个参数对模型的性能影响。
参数 |
说明 |
建议 |
|---|---|---|
numPartitions |
Spark分区数量,分区越多意味着任务数太多,每次调度耗时会增加,分区太少,会导致一些节点没有分配到任务,并且会使每个分区处理的数据量增大,从而使每个agent节点内存提高。 |
在0.5~1.5倍的总核数(executor_cores与num_executor乘积)进行网格搜索,建议使用1倍总核数。 |
maxIter |
最大迭代次数,控制模型的收敛精度,设置太大,训练时间过长,并且容易使模型过拟合,造成精度下降,设置太小,模型未收敛到最优值,造成精度不高。 |
在50~150范围内进行搜参,建议使用默认值100。对于features数量较少的数据集可适当减小迭代值。 |
inertiaCoefficient |
历史方向信息在动量计算中的权重,优化算法新增参数,正实数双精度类型,用于对精确度进行调优,通过spark.boostkit.LinearSVC.inertiaCoefficient参数设置。 |
默认值为0.5。 |
Decision Tree算法调优
简单介绍Decision Tree算法各个参数对模型的性能影响。
参数 |
说明 |
建议 |
|---|---|---|
genericPt |
数据读取时的重分区数量,分区越多意味着任务数太多,每次调度耗时会增加,分区太少,会导致一些节点没有分配到任务,并且会使每个分区处理的数据量增大,从而使每个agent节点内存提高。 |
在1~2倍的总核数(executor_cores与num_executor乘积)进行网格搜索,建议使用1倍总核数。 |
numCopiesInput |
训练数据的副本数量,优化算法新增参数,与优化算法实现有关,通过spark.boostkit.ml.rf.numTrainingDataCopies参数设置。 |
建议设置为5~10。 |
pt |
优化算法训练阶段会用到的分区数,通过spark.boostkit.ml.rf.numPartsPerTrainingDataCopy参数设置。 |
建议总核数/numcopies,向下取整。 |
featuresType |
训练样本数据中特征的存储格式,优化算法新增参数,与优化算法实现有关,通过spark.boostkit.ml.rf.binnedFeaturesDataType参数设置。 |
String,取值范围:array或者fasthashmap,缺省值为array;维度高时建议设置为fasthashmap。 |
broadcastVariables |
是否广播具有较大存储空间的变量,优化算法新增参数,与优化算法实现有关,通过spark.boostkit.ml.rf.broadcastVariables参数设置。 |
Boolean,缺省值为false,维度高时建议设置为true。 |
copyStrategy |
副本分配策略,支持normal和plus两种策略。默认设置为normal;若训练阶段存在task运行耗时明显长于其他task,可设置为plus模式,通过spark.boostkit.ml.rf.copyStrategy参数设置。 |
默认值为normal。 |
numFeaturesOptFindSplits |
特征维度阈值,当数据集的特征维度高于该值时,会触发高维特征切分点搜索的优化,缺省值为8196,通过spark.boostkit.ml.rf.numFeaturesOptimizeFindSplitsThreshold参数设置。 |
如果特征切分点搜索的stage占总时长比重大,可调低该阈值,提前触发高维优化。 |
maxDepth |
每棵子树的最大树深,取决于样本的特征的多少,即使特征多也不要使用太大,影响延缓收敛速度,并且容易过拟合。 |
常用的取值范围3~100,建议取值范围11-15。 |
maxBins |
每棵子树划分考虑的最大特征数,值越大越接近精确求解,但太大影响子树生成时间。 |
建议取值为128。 |
maxMemoryInMB |
存储统计信息的内存最大值。增加此参数允许更少的数据便利,可以提升训练速度;但增加此参数也会增加每次迭代的通信开销。 |
建议取值为2048或4096, 对于维度大的数据集可以考虑增加此参数,如设置为10240。 |
Logistic Regression算法调优
简单介绍Logistic Regression算法各个参数对模型的性能影响。
参数 |
说明 |
建议 |
|---|---|---|
numPartitions |
Spark分区数量,分区越多意味着任务数太多,每次调度耗时会增加,分区太少,会导致一些节点没有分配到任务,并且会使每个分区处理的数据量增大,从而使每个agent节点内存提高。 |
在0.5~1.5倍的总核数(executor_cores与num_executor乘积)进行网格搜索,建议使用1倍总核数。 |
Linear Regression算法调优
简单介绍Linear Regression算法各个参数对模型的性能影响。
参数 |
说明 |
建议 |
|---|---|---|
numPartitions |
Spark分区数量,分区越多意味着任务数太多,每次调度耗时会增加,分区太少,会导致一些节点没有分配到任务,并且会使每个分区处理的数据量增大,从而使每个agent节点内存提高。 |
在0.5~1.5倍的总核数(executor_cores与num_executor乘积)进行网格搜索,建议使用1倍总核数。 |
XGBoost算法调优
简单介绍XGBoost算法各个参数对模型的性能影响
参数 |
说明 |
建议 |
|---|---|---|
spark.task.cpus |
每个任务分配的cpu核数。 |
建议和executor_cores保持一致。 |
max_depth |
每棵子树的最大树深,取决于样本的特征的多少,即使特征多也不要使用太大,影响延缓收敛速度,并且容易过拟合。 |
常用的取值范围3~100,缺省值为6。 |
enable_bbgen |
是否使用批伯努利位生成算法,若为true,提高采样性能,继而提高训练性能。 |
建议为“true”。 |
rabit_enable_tcp_no_delay |
控制Rabit引擎中的通信策略。通常为true会提升训练性能。 |
建议为“true”。 |
num_workers |
运行XGBoost算法,总任务数。 |
建议和num-executors保持一致。如果超过num-executors数可能导致算法运行失败。 |
nthread |
运行XGboost算法,每个任务的并行线程数。 |
建议和executor-cores保持一致。 |
grow_policy |
修改参数,新增depthwiselossltd,控制新树节点加入树的方法,只有在tree_method被设置为hist时生效,需要依据具体训练数据来定。通常情况下,depthwise会带来更高精度,相应训练时长也会增大,lossguide与之相反;depthwiselossltd带来影响居于depthwise,lossguide之间,可通过配置进行调整。 |
String,缺省值为“depthwise”,可选值为:“depthwise”、“lossguide”、“depthwiselossltd”。 |
min_loss_ratio |
控制训练过程中树节点的剪枝程度,只有在grow_policy为depthwiselossltd时生效,取值越大,剪枝越多,速度越快,精度会有所降低。 |
Double,缺省值为0,范围[0,1)。 |
sampling_strategy |
控制训练过程中的采样策略,采样频率eachTree>eachIteration>multiIteration>alliteration。采样频率越低,采样时间开销越小,精度可能产生下降。gossSytle是基于梯度的采样,开销稍大,精度更高。 |
String,缺省值为“eachTree”,可选值为,“eachTree”,“eachIteration”,“alliteration”,“multiIteration”,“gossStyle”。 |
sampling_step |
控制采样的间隔轮次,只有sampling_strategy设置为multiIteration时生效。间隔越大,采样频率越低,采样开销越小,精度可能产生下降。 |
Int,缺省值为:1,可选值范围:[1,+∞)。 |
auto_subsample |
控制是否采用自动减少采样率策略。开启后,自动尝试使用较小采样频率进行采样,采样率搜索过程可能带来时间开销,若搜索到合适的小采样率,训练过程时间开销会减小。 |
Boolean,缺省值为:“false”,可选值为:“true”,“false”。 |
auto_k |
控制自动减少采样率策略中的轮次,只有auto_subsample设置为true时生效。值越大,采样率搜索时间开销越大,但搜索结果更准确。 |
Int,缺省值为:1,可选值范围:[1,+∞)。 |
auto_subsample_ratio |
设置自动减少采样率的比例,为一个Array数组,数组元素升序排列,数组中元素越多 ,尝试搜索的采样率次数越多,时间开销可能增大,搜索结果可能越准确。数组中每个元素越小,代表搜索的采样率的值越小。 |
Array[Double],缺省值为:Array(0.05,0.1,0.2,0.4,0.8,1.0),可选值范围:(0,1]。 |
auto_r |
控制允许的自动减少采样率带来的错误率上升。取值越小,表示容许更大的错误率。 |
Double,缺省值为:0.95,可选值范围:(0,1]。 |
random_split_denom |
控制候选分割点的使用比例。取值越大,训练时长可能减小,误差可能相对增加。 |
Int,缺省值为:1,可选值范围:[1,+∞)。 |
default_direction |
控制缺省值的默认方向。缺省值为“learn”,若选用“left”或“right”,训练时长可能减小,精度可能降低。 |
String,可选值为:“left”,“right”,“learn”。 |
KNN算法调优
简单介绍KNN算法各个参数对模型的性能影响
参数 |
说明 |
建议 |
|---|---|---|
numPartitions |
Spark分区数量,分区越多意味着任务数太多,每次调度耗时会增加,分区太少,会导致一些节点没有分配到任务,并且会使每个分区处理的数据量增大,从而使每个agent节点内存提高。 |
在0.5~1.5倍的总核数(executor_cores与num_executor乘积)进行网格搜索,建议使用1倍总核数。 |
testBatchSize |
推理阶段单次计算样本数量,数量越多,内存占用越大。优化算法相对于开源KNN算法新增参数,可以在transform阶段使用KNNModel.setTestBatchSize()方法传入参数。 |
正整数,缺省值为1024。 |
