网络NUMA绑核
原理
当网卡收到大量请求时,会产生大量的中断,通知内核有新的数据包,然后内核调用中断处理程序响应,把数据包从网卡拷贝到内存。当网卡只存在一个队列时,同一时间数据包的拷贝只能由某一个core处理,无法发挥多核优势,因此引入了网卡多队列机制,这样同一时间不同core可以分别从不同网卡队列中取数据包。
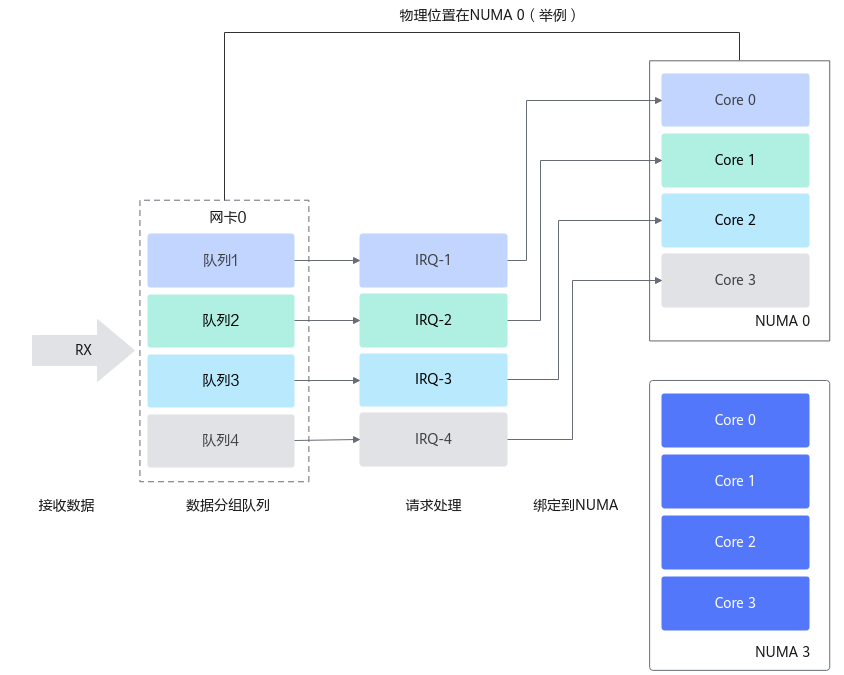
在网卡开启多队列时,操作系统通过Irqbalance服务来确定网卡队列中的网络数据包交由哪个CPU core处理,但是当处理中断的CPU core和网卡不在一个NUMA时,会触发跨NUMA访问内存。因此,我们可以将处理网卡中断的CPU core设置在网卡所在的NUMA上,从而减少跨NUMA的内存访问所带来的额外开销,提升网络处理性能。
图1 自动绑定:中断绑定随机,出现跨NUMA访问内存
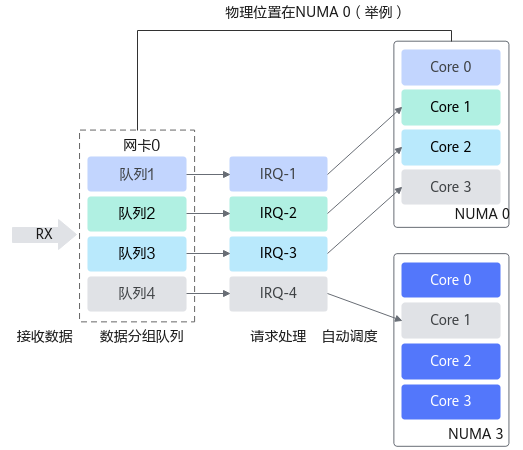
图2 NUMA绑定:中断绑定到指定核,避免跨NUMA访问内存
修改方式
- 停止irqbalance。
# systemctl stop irqbalance.service # systemctl disable irqbalance.service
- 设置网卡队列个数为CPU的核数。
# ethtool -L ethx combined 48
- 查询中断号。
# cat /proc/interrupts | grep $eth | awk -F ':' '{print $1}' - 根据中断号,将每个中断分别绑定在一个核上,其中cpuNumber是core的编号,从0开始。
# echo $cpuNumber > /proc/irq/$irq/smp_affinity_list
父主题: 优化方法
