示例2:MPI+OpenMP应用并行调试
本示例主要是演示如何使用编译调试工具的HPC并行应用调试功能,调试MPI+OpenMP应用,帮助用户基于该工具快速实现并行调试。
- 请从GitHub获取待使用的MPI程序源文件mpi_openmp_demo.c。
- 在VS Code工具的资源管理器中打开本地的解压文件夹(devkitdemo-devkitdemo-23.0.1/Compiler_and_Debugger/mpi_demo)。进入到鲲鹏DevKit插件,单击“开发”按钮,在编译调试区域单击“调试”,打开调试页面。图1 选择调试

- 选择“HPC并行应用”,配置MPI+OpenMP应用调试参数,参数说明如表1所示。图2 配置MPI+OpenMP应用调试参数
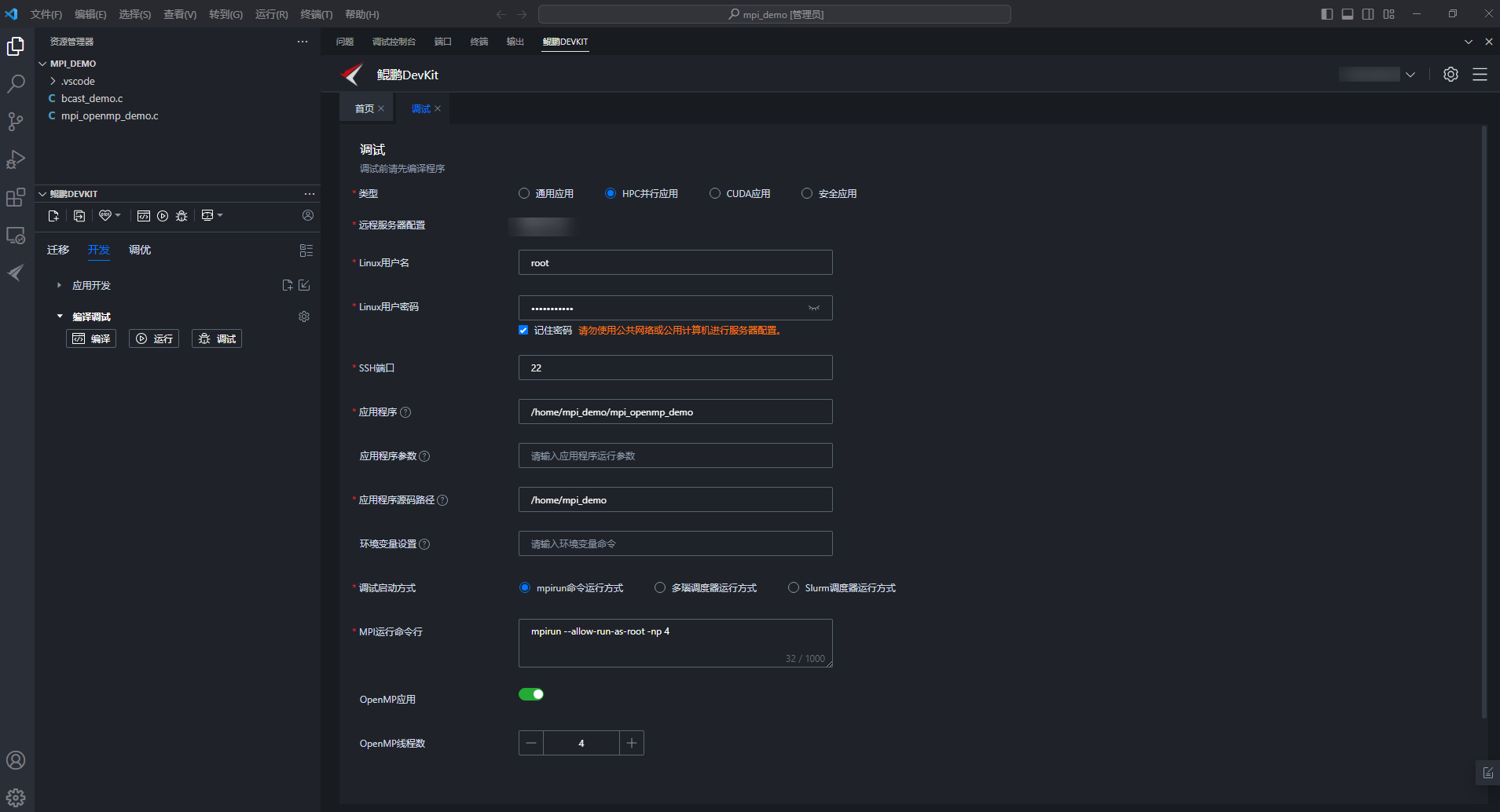
表1 HPC并行应用调试参数说明 参数
说明
远程服务器配置
进行HPC并行应用调试的目标服务器。
Linux用户名
输入启动MPI+OpenMP应用的Linux用户名称。
说明:root用户拥有最高权限,为了避免给系统带来不必要的风险,建议使用非root用户进行调试。
Linux用户密码
使用的Linux用户密码。
SSH端口
输入启动MPI+OpenMP应用的服务器SSH端口号。
应用程序
输入的MPI+OpenMP应用,支持动态检索并显示应用程序路径。
请给Linux用户添加当前MPI+OpenMP应用的可读权限以及应用所在目录的可读、可写和可执行权限。说明:- MPI+OpenMP应用要为可执行文件。
- 若MPI+OpenMP应用中无源码信息,则调试器默认以汇编形式进行调试。
应用程序参数(可选)
传递给应用程序运行的参数,若存在多个参数需使用空格隔开。
请给Linux用户添加应用程序所在目录的可读、可写、可执行权限及应用程序所在目录父目录的可执行权限。
应用程序源码路径
源码和MPI+OpenMP应用存放的共享路径,支持动态检索并显示应用程序源码工作目录。
- 若MPI+OpenMP应用已配置共享路径,源码与MPI+OpenMP应用都应存放在共享路径下。
- 请给Linux用户添加当前MPI应用源码路径的可读、可执行权限及源码文件所在目录父目录的可执行权限。
环境变量设置(可选)
输入运行HPC并行应用所需要的环境变量,有以下3种方式可选择,可根据实际情况进行修改。
- export PATH=$PATH:/path/to/mpi
- source /configure/mpi/path/file
- module load /mpi/modulefiles
调试启动方式
调试启动方式可选:
mpirun 命令运行方式多瑙调度器 运行方式Slurm调度器 运行方式
MPI运行命令行
输入的mpirun命令以及对应的命令参数,rank数目为1 ~ 2048。
多瑙调度器运行命令行
输入的多瑙调度器命令以及对应的命令参数。
Slurm调度器运行命令行
输入的srun命令以及对应的命令参数。
OpenMP应用
勾选后,需要输入OpenMP线程数。
OpenMP线程数
输入的OpenMP应用thread数量,取值范围1 ~ 1024。
死锁检测(可选)
勾选后,需要输入死锁超时时间。
死锁超时时间(s)(可选)
死锁超时时间,默认为10秒,取值范围10秒 ~ 60秒。
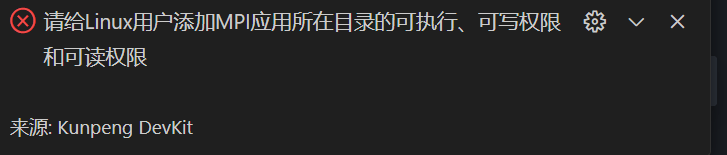
- 参数填写完成后,单击“开始调试”,若右下角提示权限问题,如图3所示,请执行以下命令解决。
chmod 700 -R 目录名称/
- 再次单击“开始调试”,启动HPC并行应用调试并读取rank状态。图4 启动HPC并行应用调试
 图5 读取rank状态
图5 读取rank状态
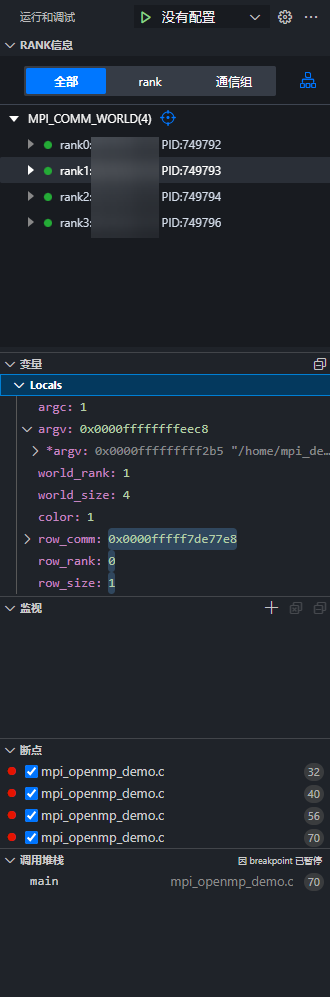
- 在rank状态读取过程中,若rank状态读取全部成功,会自动跳转到MPI+OpenMP应用调试页面。运行和调试区、源码区和调试功能区,运行和调试区域包括调试信息区和rank信息区,如图6所示。
- HPC并行应用调试支持三种调试粒度,分别为“全部”调试、“rank”调试或“通信组”调试。图7 选择调试方式
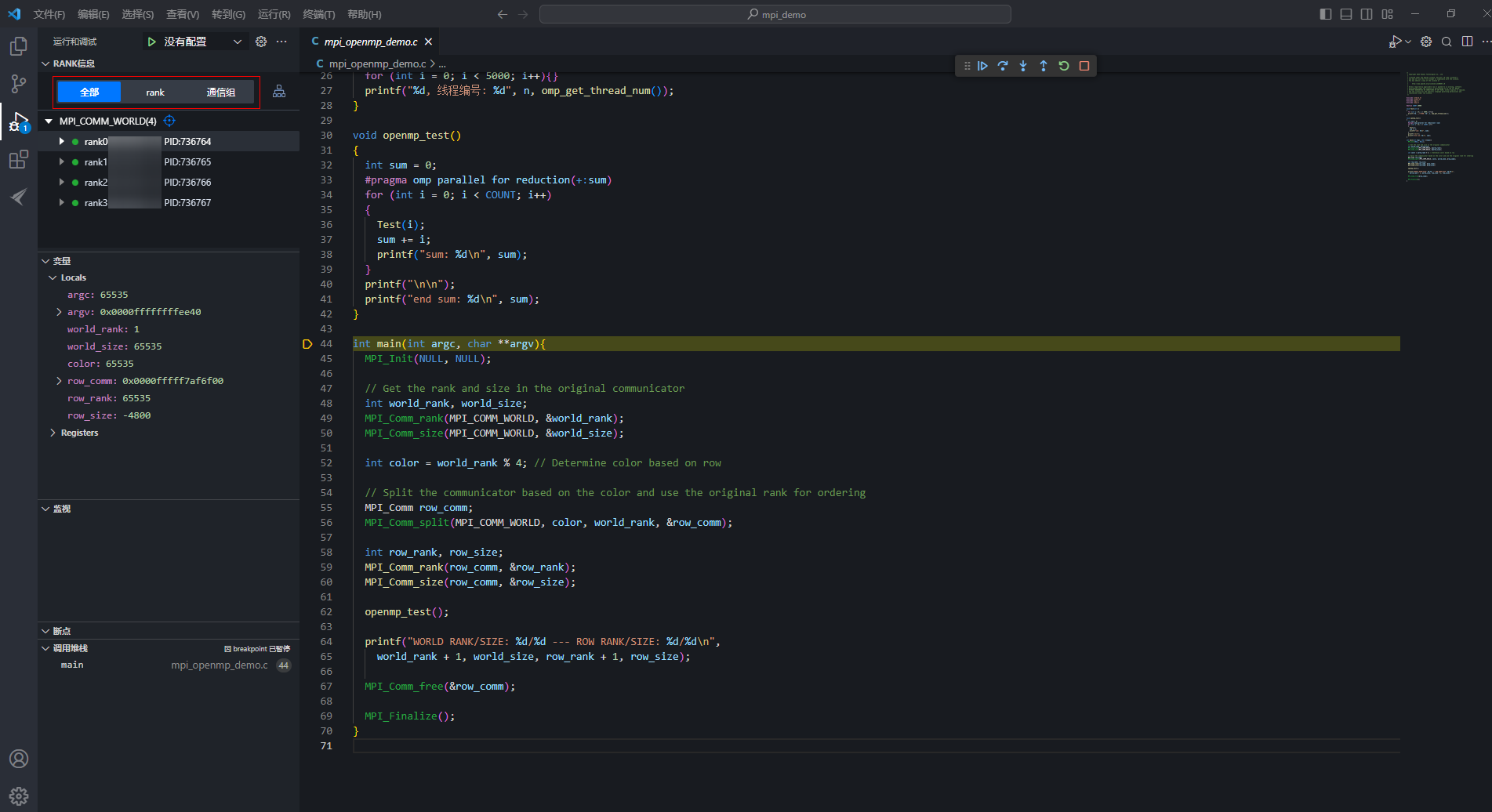
表2 调试粒度说明 调试方式
效果
全部
在RANK信息区域选择“全部”方式进行调试,选择某一个rank,对其进行调试会应用到全部rank。
rank
在RANK信息区域选择“rank”方式进行调试,对单一rank进行调试。
通信组
在RANK信息区域选择“通信组”方式进行调试,选择通信组中的某一个rank,对其进行调试会应用到整个通信组。
- 可以单击调试功能区的操作按钮来调试MPI+OpenMP应用。
表3 调试按钮操作描述 图标
操作
操作描述

继续
单击执行到下一个断点

暂停
单击中断正在执行的程序

单步跳过
单击执行到下一行

单步调试
单击步入函数

单步跳出
单击步出函数

重启
单击后重新启动调试

停止
单击后停止调试

操作描述中有“(进程级/线程级)”字样的按钮,其意义为:选中rank后单击按钮为进程级调试动作,选中thread后单击按钮为线程级调试动作。
- RANK信息区域选择“全部”调试方式,在56行代码处、32行代码处和36行代码处设置断点,再继续执行后续操作。
支持添加条件断点(表达式、命中次数),条件断点支持修改、启用、禁用和删除。表达式断点是指表达式成立时中断该程序,命中次数断点是指命中指定的次数时中断该程序(当大于等于设置的命中次数时,均可进入断点中)。
- 选择“全部”调试方式,单击“
 继续”按钮,代码执行到56行,再单击“
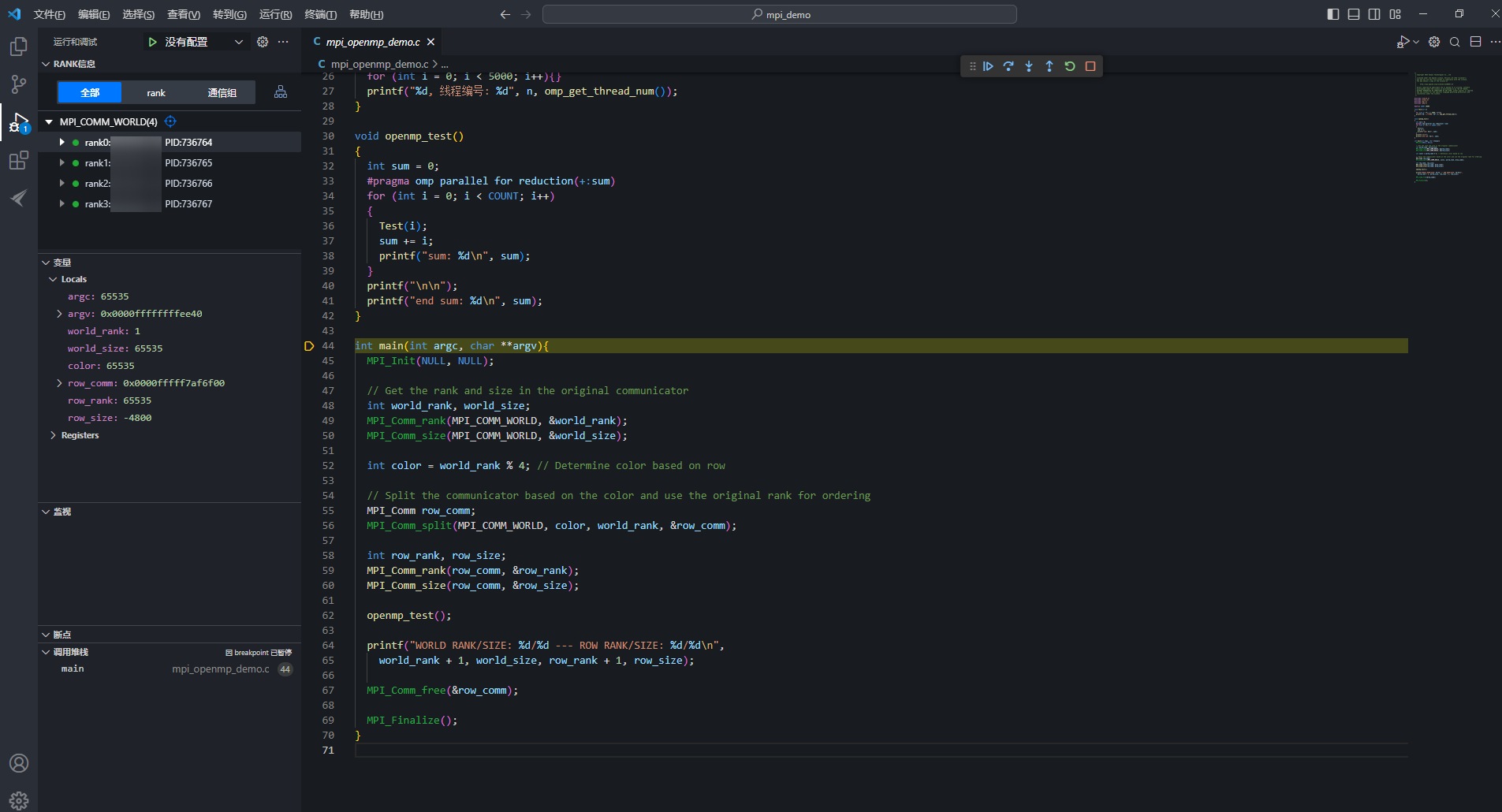
继续”按钮,代码执行到56行,再单击“ 下一步”执行MPI_Comm_split(MPI_COMM_WORLD, color, rankNum, &row_comm)函数,该函数可将所有的rank进行通信分组。这里将4个rank生成4个通信子组。图8 生成4个通信子组
下一步”执行MPI_Comm_split(MPI_COMM_WORLD, color, rankNum, &row_comm)函数,该函数可将所有的rank进行通信分组。这里将4个rank生成4个通信子组。图8 生成4个通信子组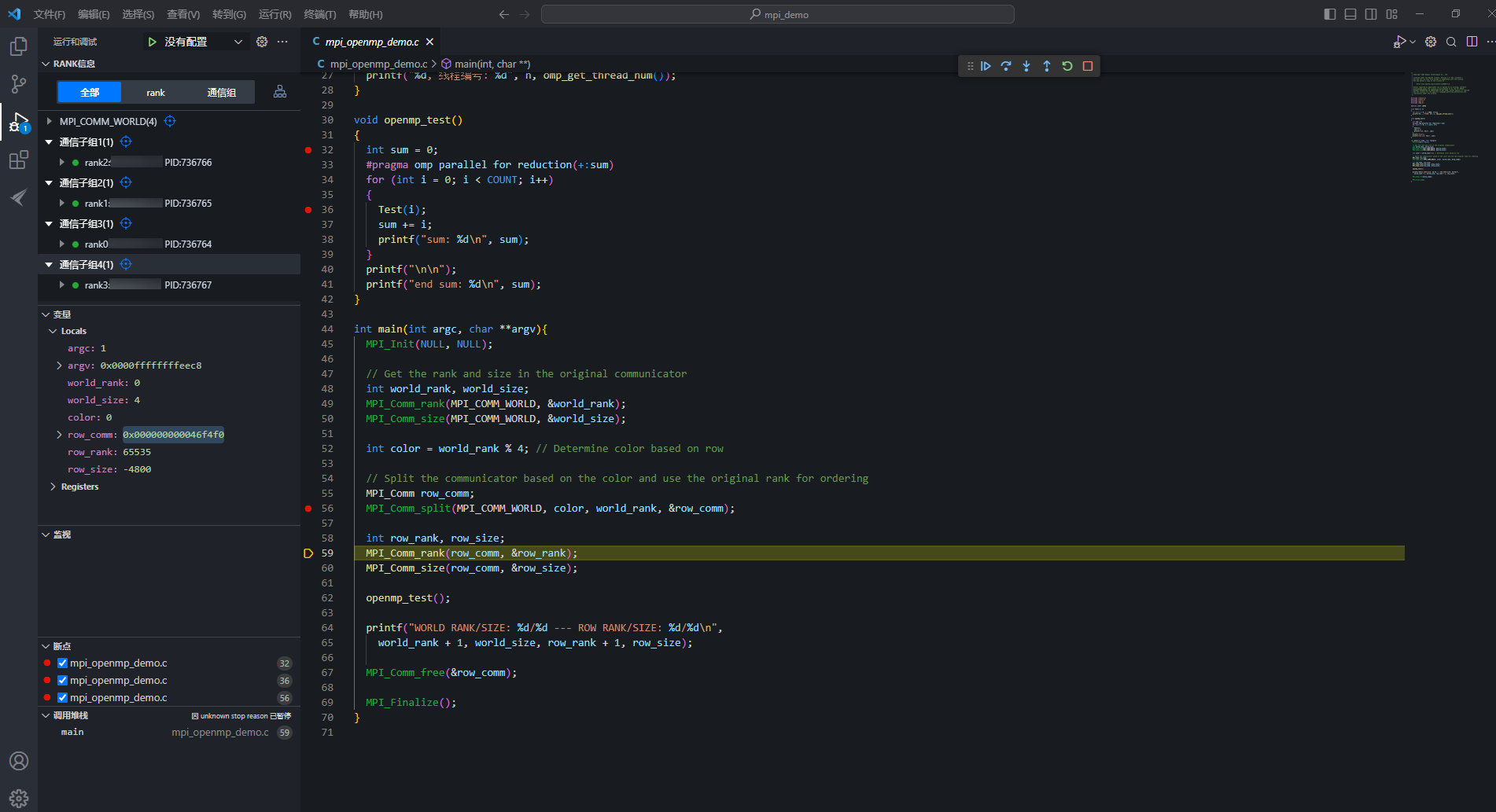
MPI_Comm_split(MPI_COMM_WORLD, color, rankNum, &row_comm)是一个用于创建新的通信子组的函数。
- 第一个参数MPI_COMM_WORLD是通信组,在这个函数中,原始的通信组并没有消失,但是在每个进程中都会创建一个新的通信组;
- 第二个参数color确定每个rank将属于哪个新的通信子组;
- 第三个参数rankNum确定每个新通信组中的顺序(秩),传递rankNum最小值的进程将为0,下一个最小值将为1,以此类推;
- 第四个参数row_comm是MPI如何将新的通信子组返回给用户。
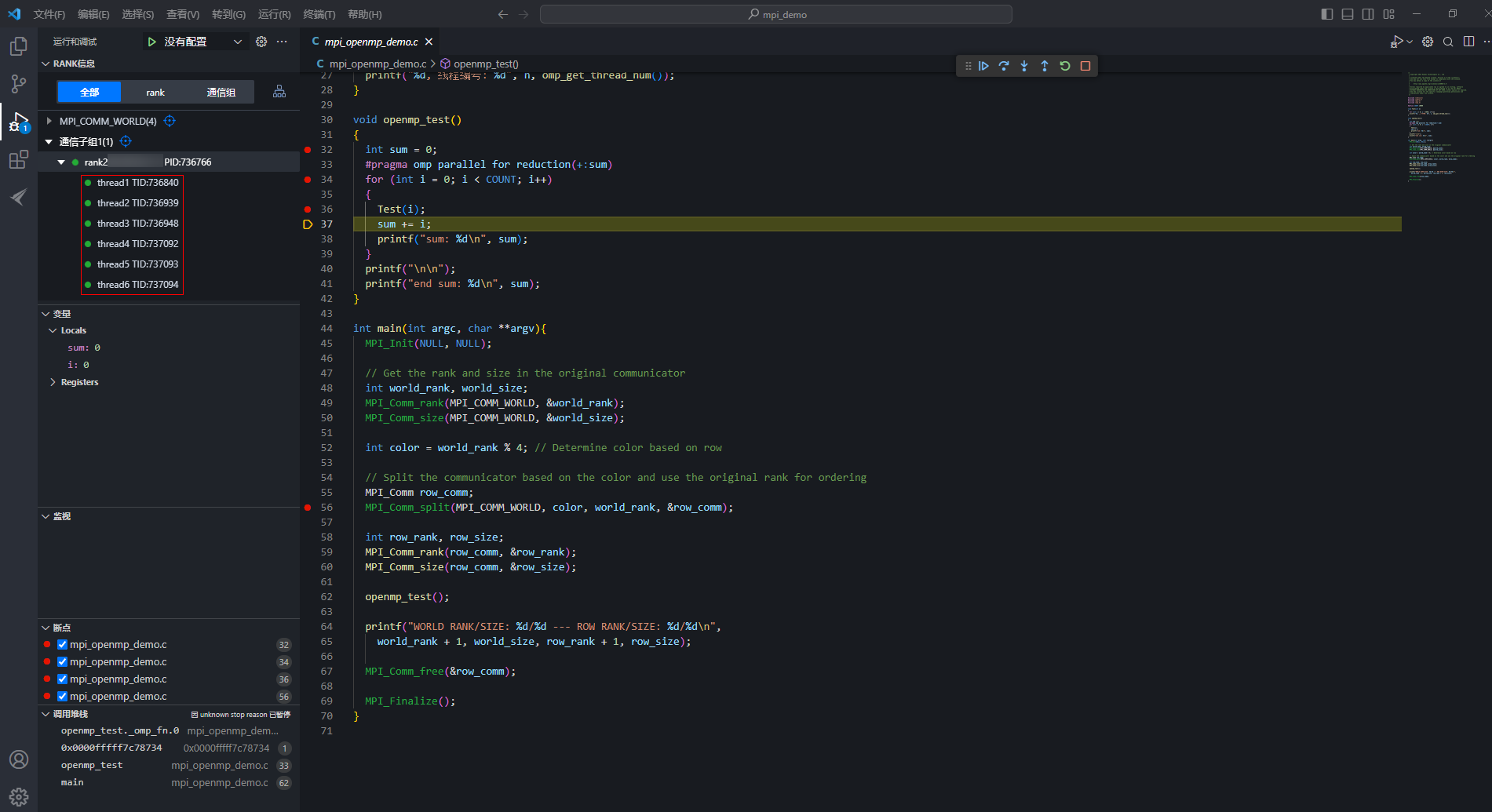
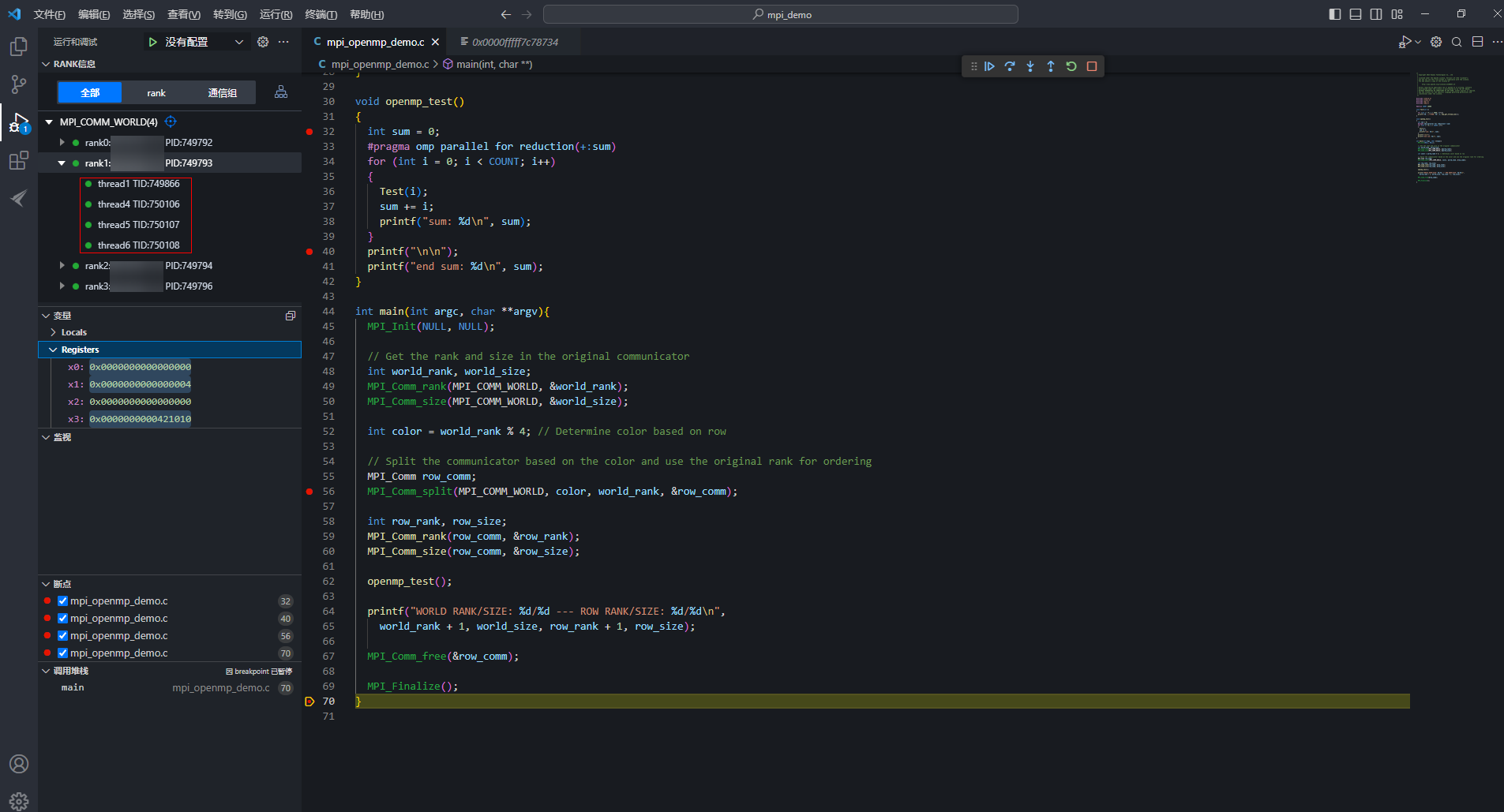
- 生成4个通信子组后,所有rank的源码执行到59行代码处,单击通信子组1中的rank,展开有3个线程,thread1、thread2和thread3。图9 查看线程
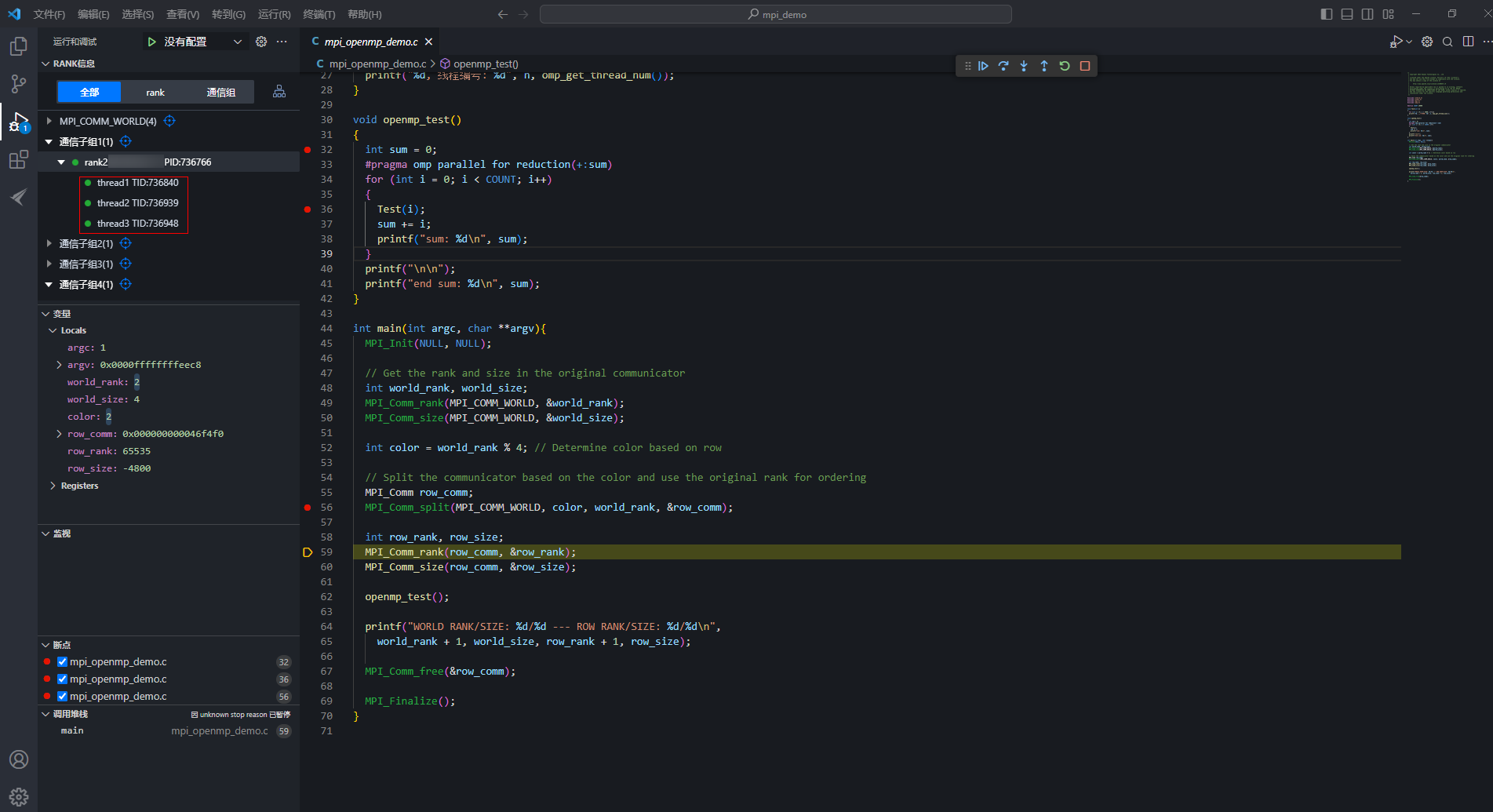
thread1是MPI应用的主线程,thread2、thread3是MPI应用的辅助线程,辅助线程不展示源码,仅显示汇编代码。
- 单击某个rank,单击“
 继续”按钮,代码执行到32行代码处,单击“
继续”按钮,代码执行到32行代码处,单击“ 下一步”执行到OpenMP导语一行。在OpenMP导语后的第一行设置断点再单击“
下一步”执行到OpenMP导语一行。在OpenMP导语后的第一行设置断点再单击“ 继续”进入OpenMP语句产生子线程,如图10所示;若单击“
继续”进入OpenMP语句产生子线程,如图10所示;若单击“ 下一步”则会一次性执行完OpenMP导语代码块。
下一步”则会一次性执行完OpenMP导语代码块。
- 配置参数时定义的线程数为4,当执行for语句产生子线程后,展开rank为6个线程,thread1为主线程,thread2、thread3为MPI的辅助线程,thread4、thread5、thread6为OpenMP的辅助线程。thread1、thread4、thread5、thread6加起来共4个线程,OpenMP的辅助线程只会执行OpenMP导语语句块中的内容,堆栈停留在main._omp_fn()的位置。
- 主线程能运行到OpenMP导语语句块后面的代码如40行代码处。OpenMP的辅助线程则无法运行到该位置,执行完OpenMP导语语句块后,辅助线程以线程残余的状态保留着。
- 目前thread1、thread4、thread5、thread6都存在36行断点。选中thread4,进行线程操作,单击“
 继续”按钮,此时即为线程级调试。此处即为thread4执行Test(i)函数,查看thread4线程调试信息中的变量值,i值从2500变为2501,其余三个线程的i值保持不变。选中rank,进行rank操作,单击“
继续”按钮,此时即为线程级调试。此处即为thread4执行Test(i)函数,查看thread4线程调试信息中的变量值,i值从2500变为2501,其余三个线程的i值保持不变。选中rank,进行rank操作,单击“ 继续”按钮,rank下所有thread都会继续运行。因只要有一个线程暂停运行,其他线程也暂停运行,所以各线程执行的位置各不相同,变量i值不一定都会增加1。
继续”按钮,rank下所有thread都会继续运行。因只要有一个线程暂停运行,其他线程也暂停运行,所以各线程执行的位置各不相同,变量i值不一定都会增加1。- 线程与线程之间的运行不同步,线程各自设置的线程级断点也相互隔离;
- rank层级的调试操作会同步到当前rank下的所有线程。选中某个thread的调试操作只会影响到这一个线程。(调试粒度不同,同步到rank以及线程的调试操作范围也不一样。)
- 线程级调试时,一个rank下只有一个线程在运行。
- 线程级调试时切换线程,会暂停当前线程的运行,然后再切换到另一个线程。
图11 线程级调试
 图12 rank级调试
图12 rank级调试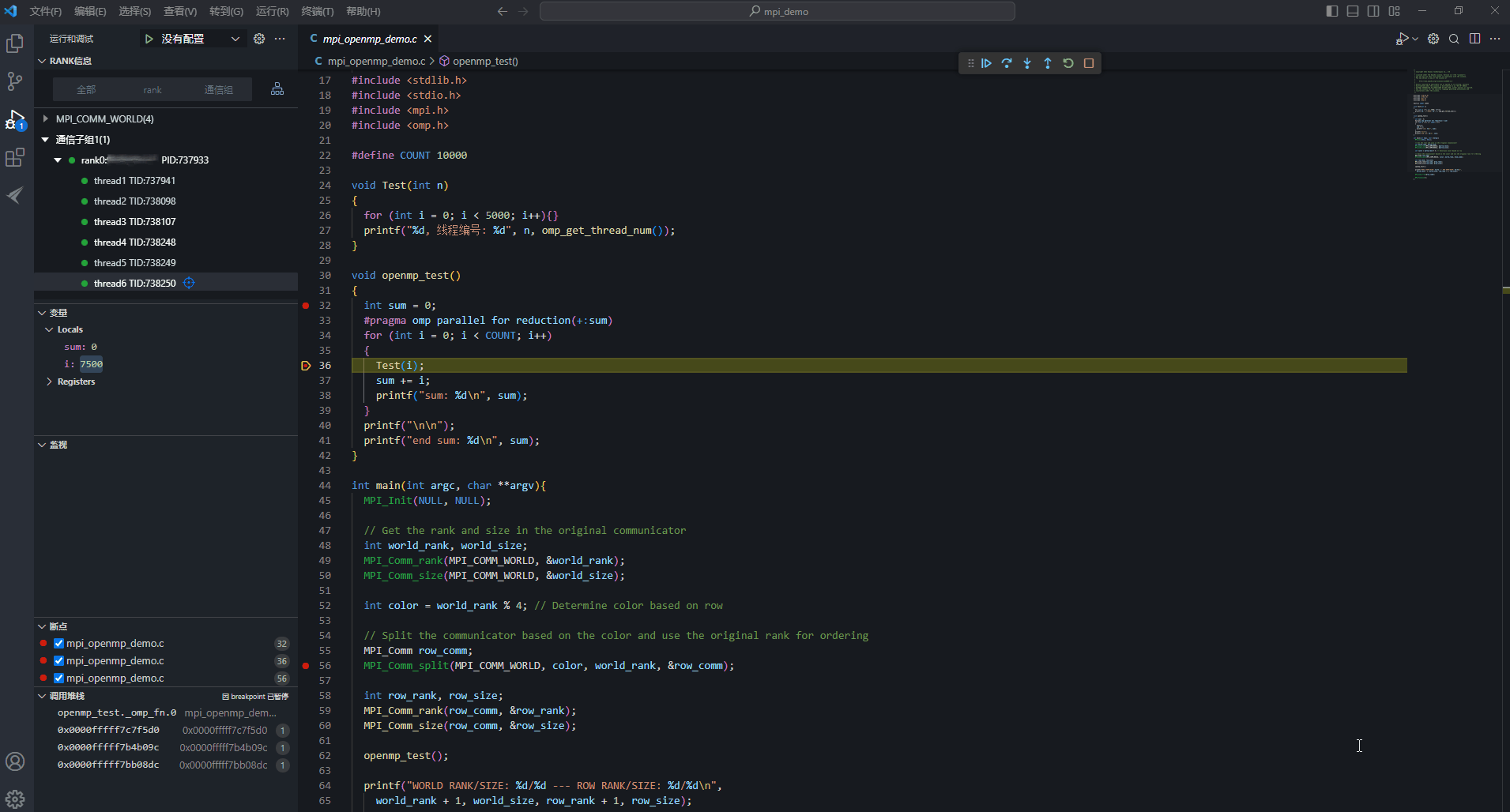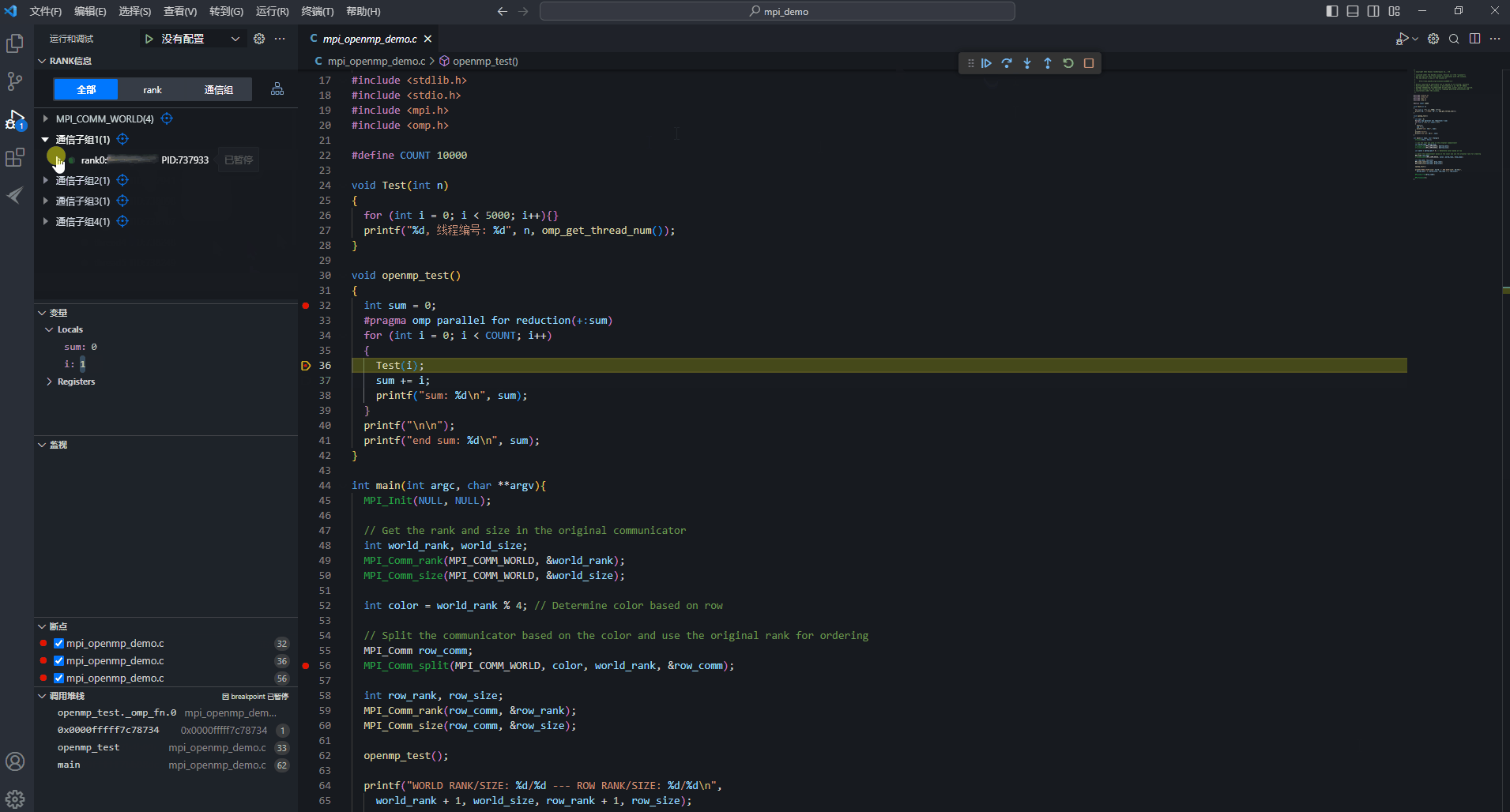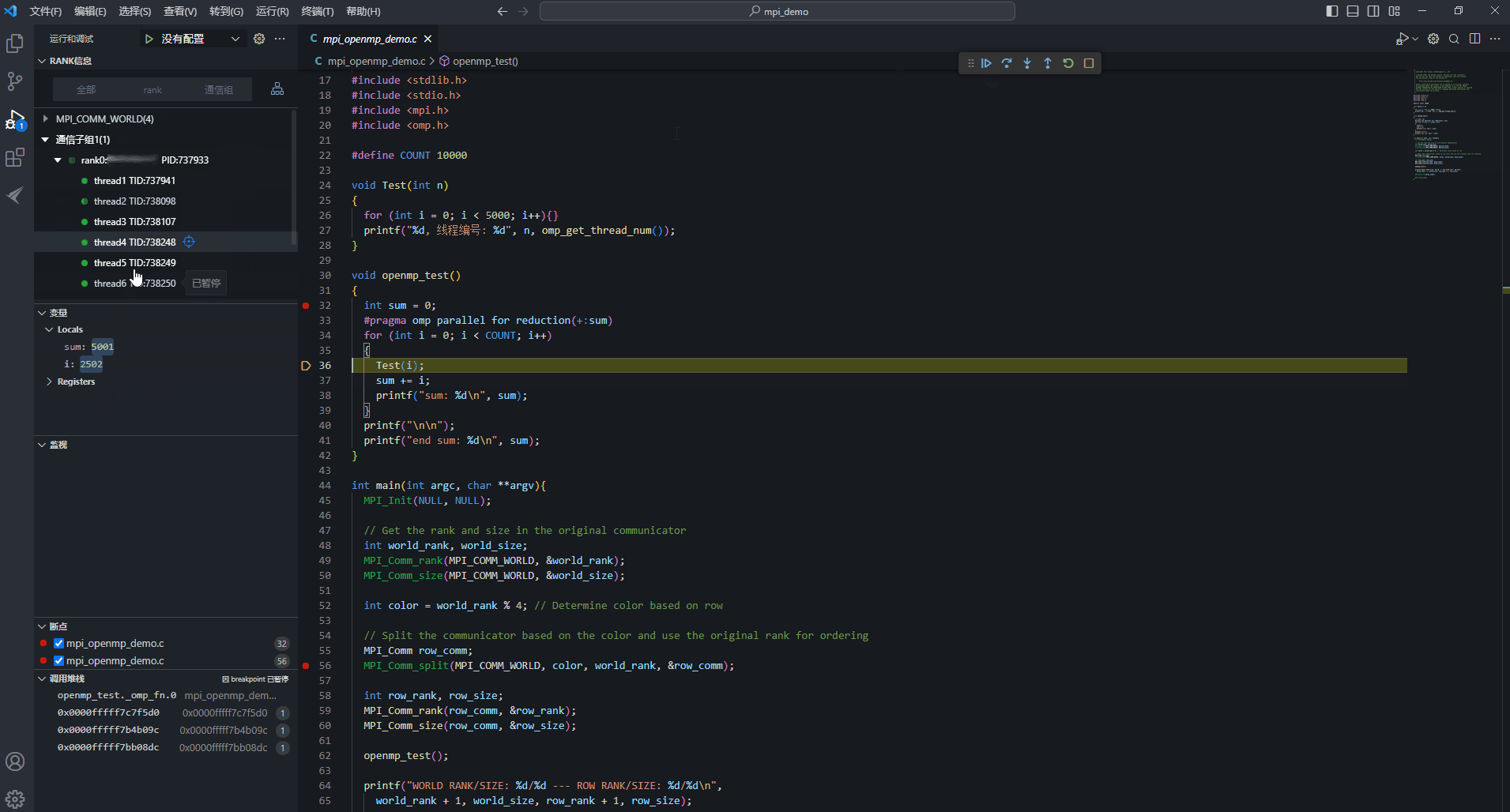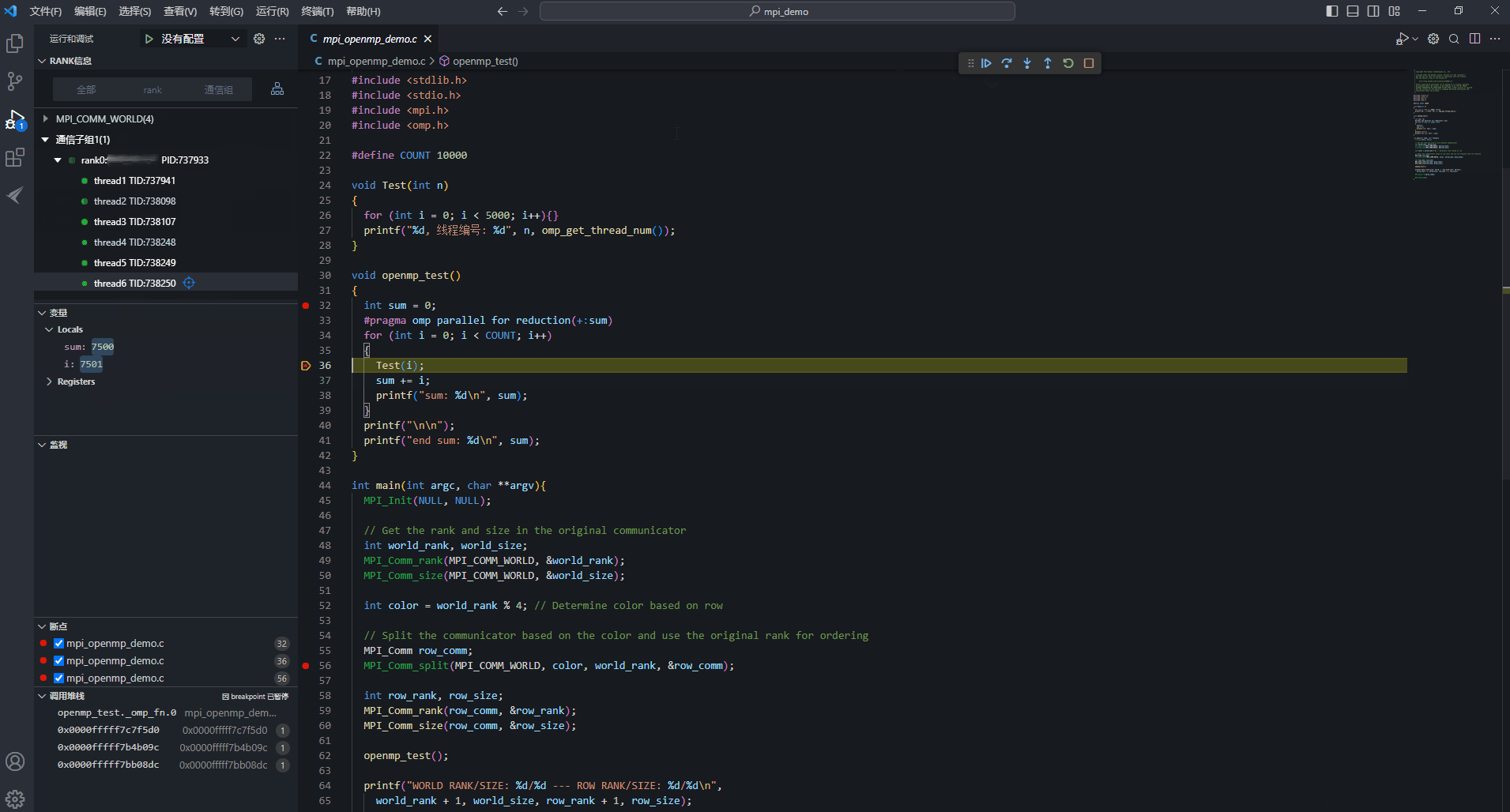
- 选中thread设置的断点即为线程级断点,选中rank设置的断点即为rank级断点。
- 各个线程的线程级断点相互隔离。
- rank级断点,每个thread都会展示出来。thread级断点,只会在各自的thread下展示。
- 若单击rank,则会把rank级断点和其下各thread的thread级断点都查询出来并展示。
- 在26行代码处打上断点,代码中OpenMP导语#pragma omp parallel for reduction(+:sum),意义为多线程共同执行for循环。此OpenMP语句程序表现为4个线程平分这10000次循环,并且每个线程都有独自保存sum值的能力。OpenMP导语代码块结束后,主线程再将各个线程计算得出的sum值汇总。图13 thread4 sum汇总
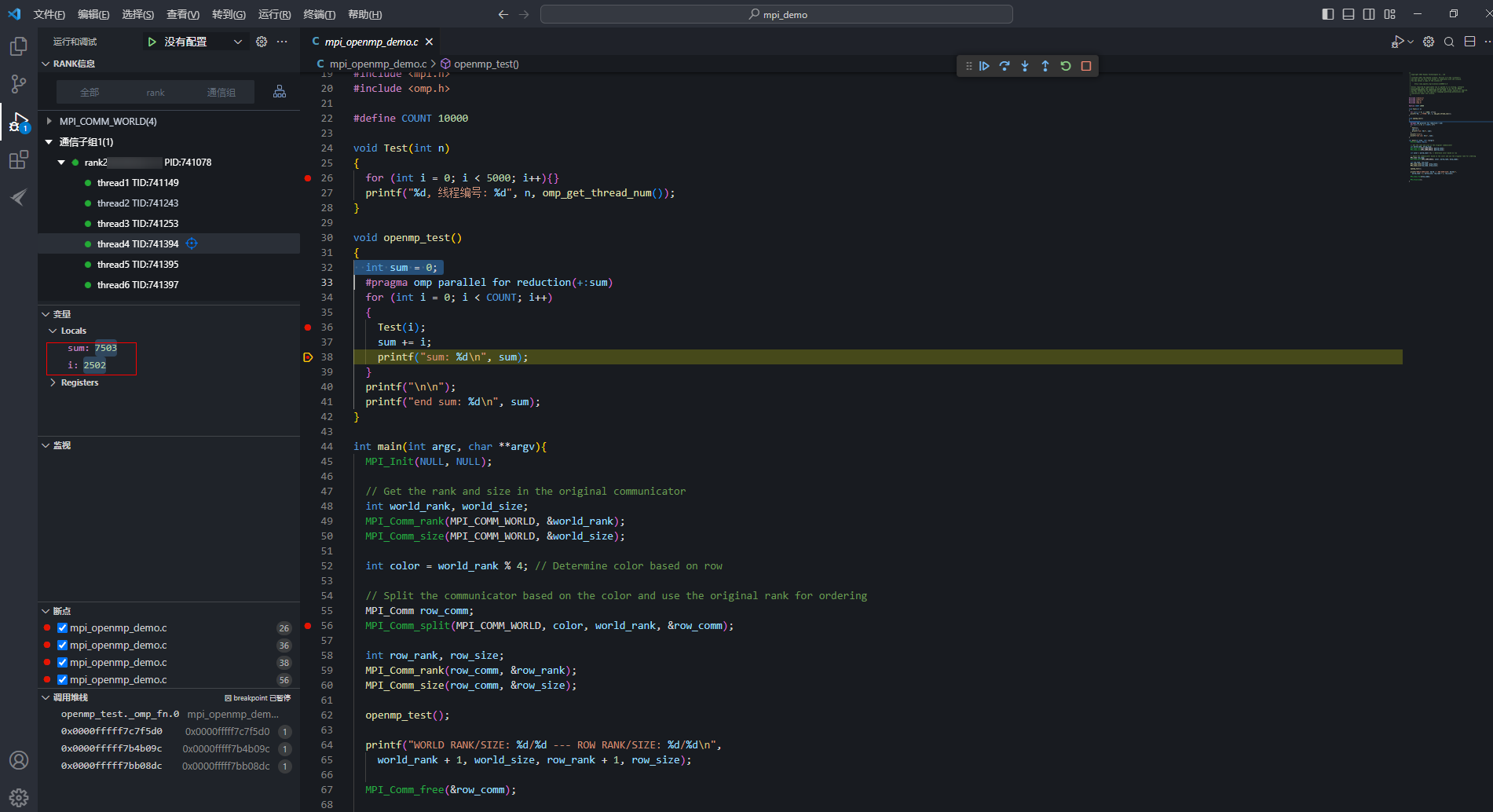
- reduction使用范围为:+,-,*,&,|,&&,||等。
- 调试thread4之前,sum值为5001,i值为2502,执行Test(i)函数,跳转到26行代码处执行for循环,执行完成后单击“
 单步跳出”步出Test(i)函数,执行“sum += i;”,可以看到sum为7503,其他thread调试执行也是同样的流程,循环2500次。
单步跳出”步出Test(i)函数,执行“sum += i;”,可以看到sum为7503,其他thread调试执行也是同样的流程,循环2500次。
- 循环结束后,四个线程把自己的sum累加起来作为最后的输出,主线程输出最后的结果,辅助线程统一显示汇编代码,OpenMP部分的线程级调试就已经结束了。图14 主线程输出结果
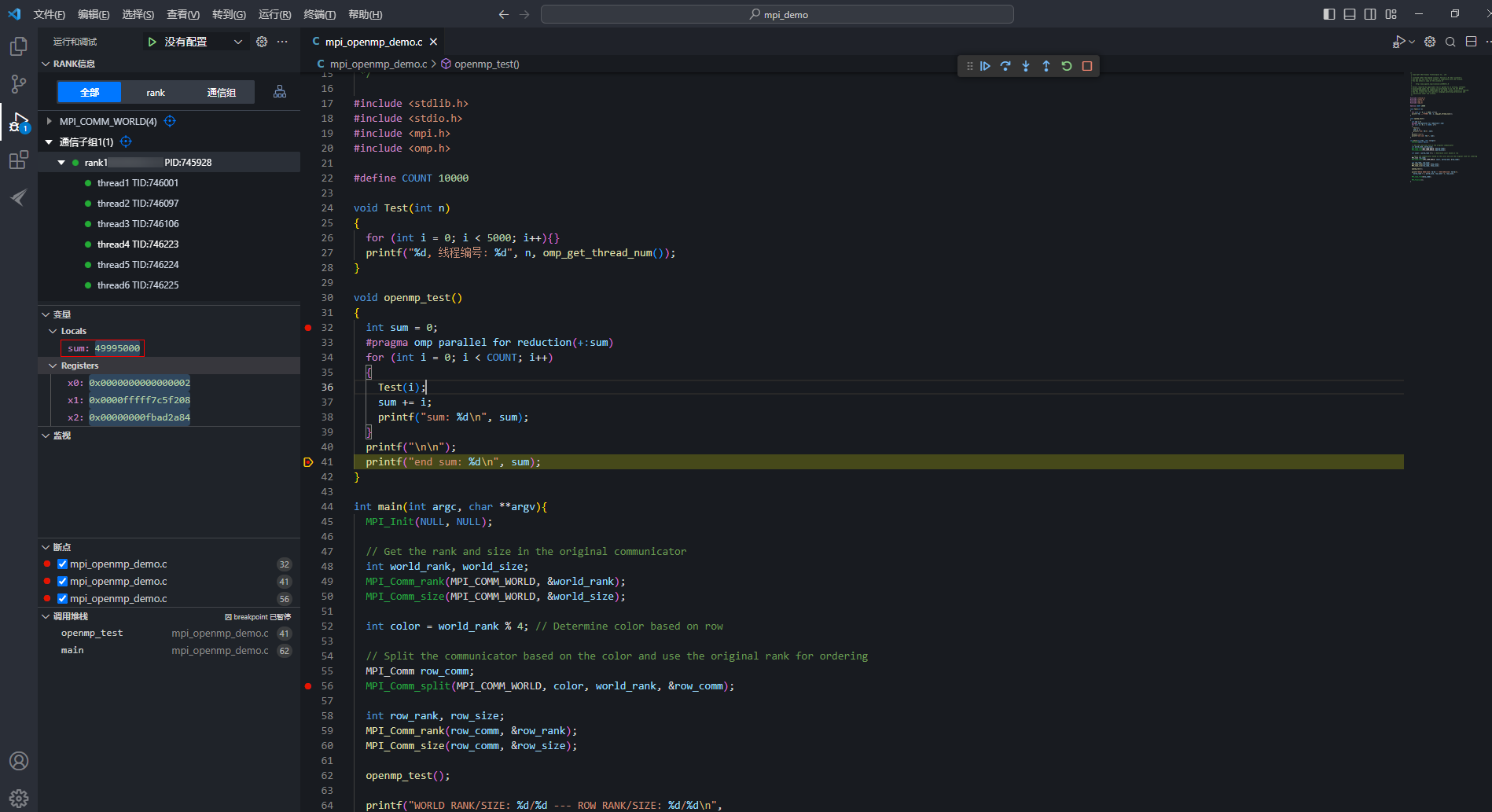 图15 辅助线程显示汇编
图15 辅助线程显示汇编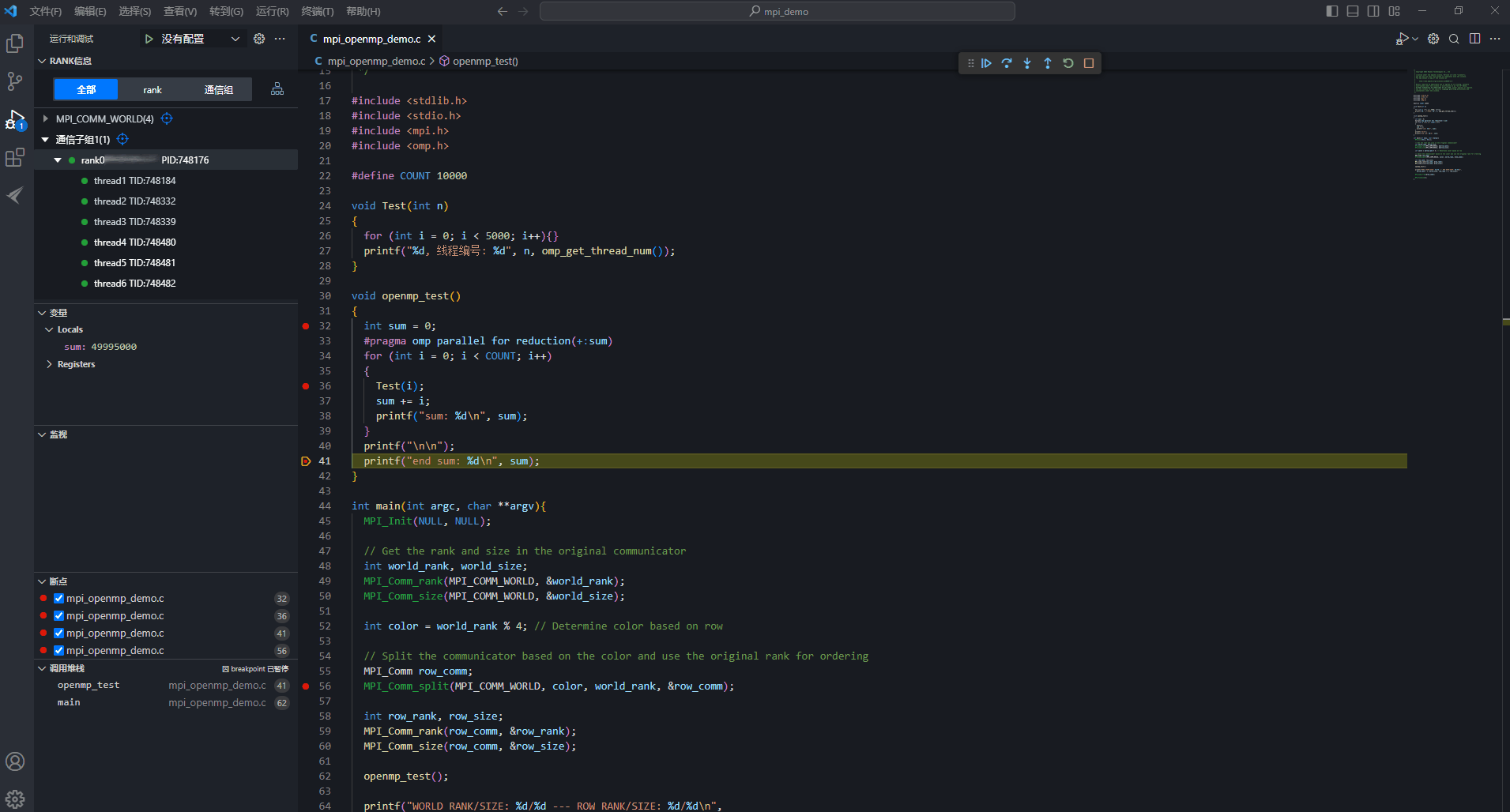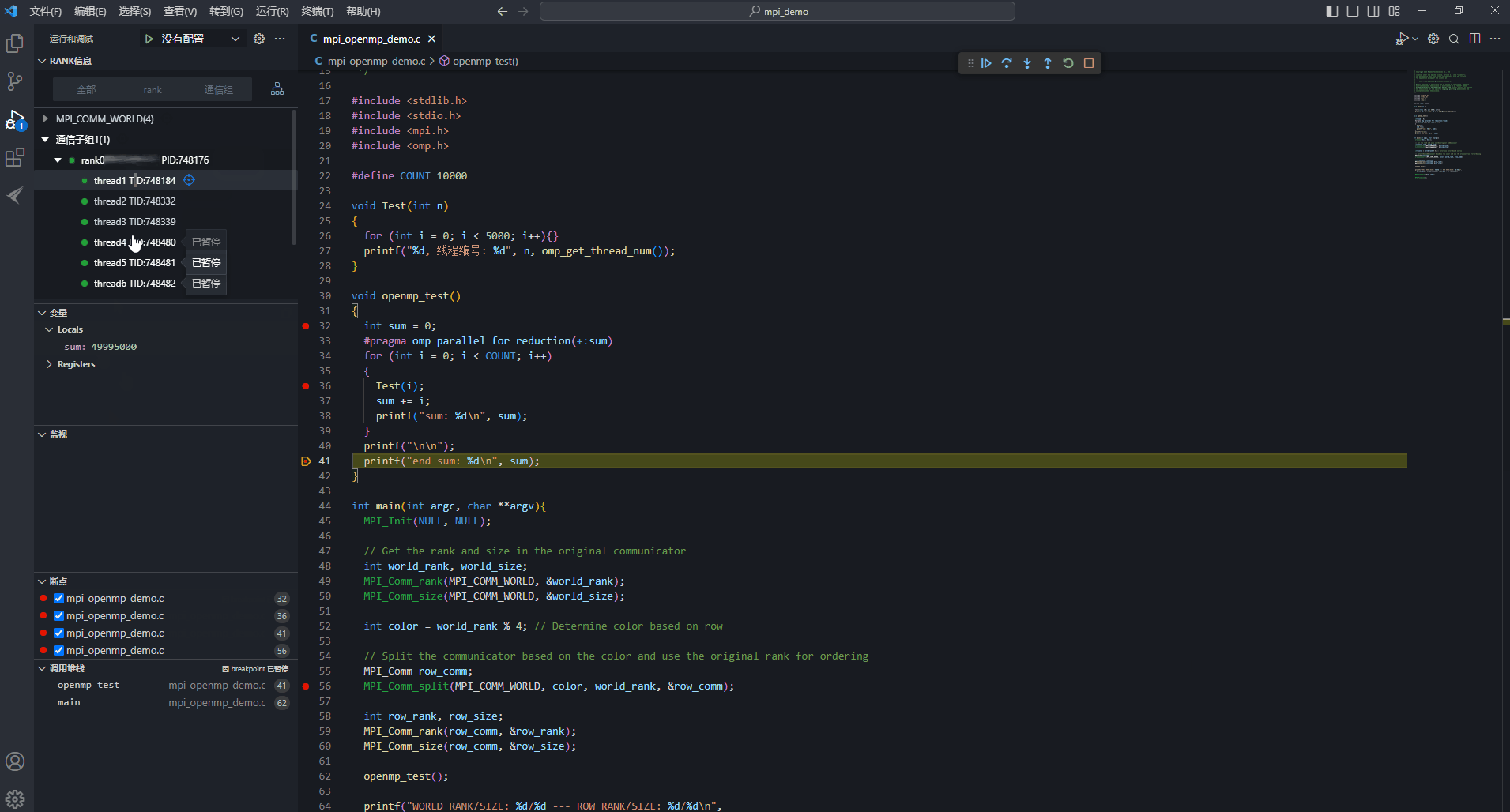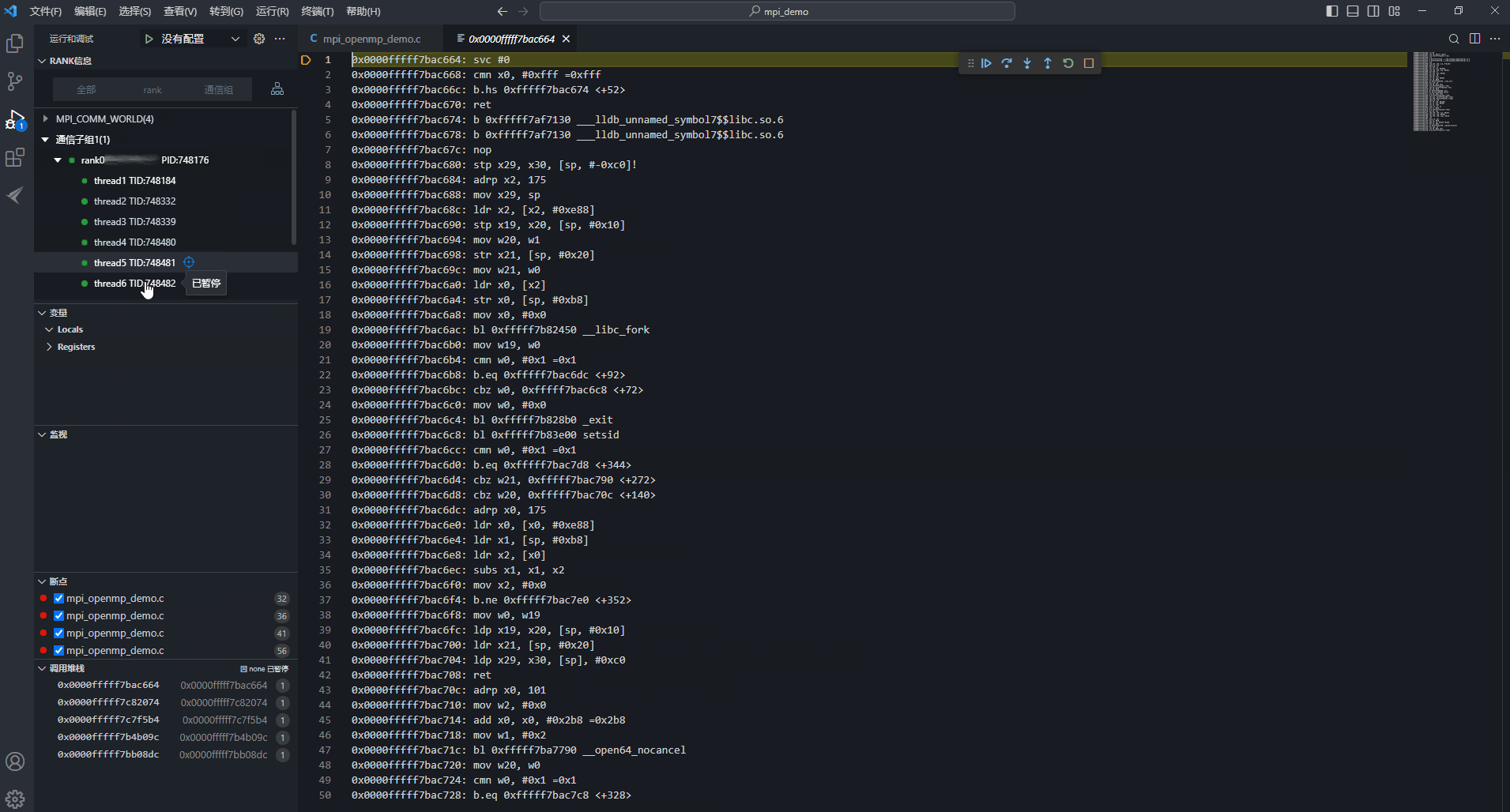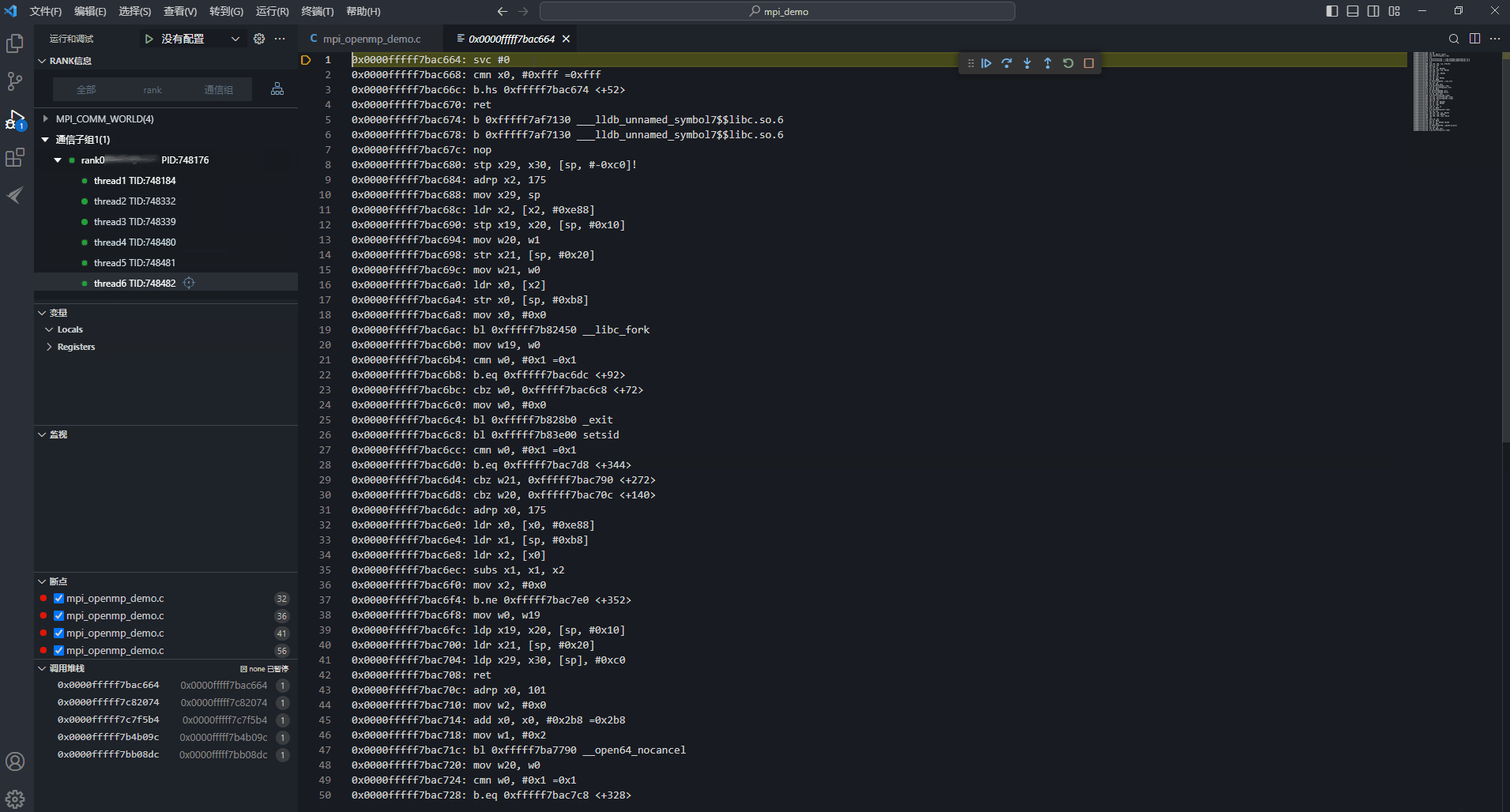
- 在70行代码处打上断点,单击“
 继续”按钮,执行MPI_Finalize()函数,会释放MPI的thread2、thread3辅助线程。如图16所示。
继续”按钮,执行MPI_Finalize()函数,会释放MPI的thread2、thread3辅助线程。如图16所示。
MPI_Finalize()函数是指终止调用MPI进程的执行环境,执行该函数会清理掉与MPI应用相关的状态。
- 单击“
 ”按钮,在VS Code面板上能看到通信子组的变化概览,每100ms显示通信子组的变化。通信子组的变化用不同颜色的菱形来区分,蓝色表示通信子组创建,紫色表示通信子组清除,黄色表示100ms内存在通信子组创建和通信子组清除。图17 查看通信子组变化概览
”按钮,在VS Code面板上能看到通信子组的变化概览,每100ms显示通信子组的变化。通信子组的变化用不同颜色的菱形来区分,蓝色表示通信子组创建,紫色表示通信子组清除,黄色表示100ms内存在通信子组创建和通信子组清除。图17 查看通信子组变化概览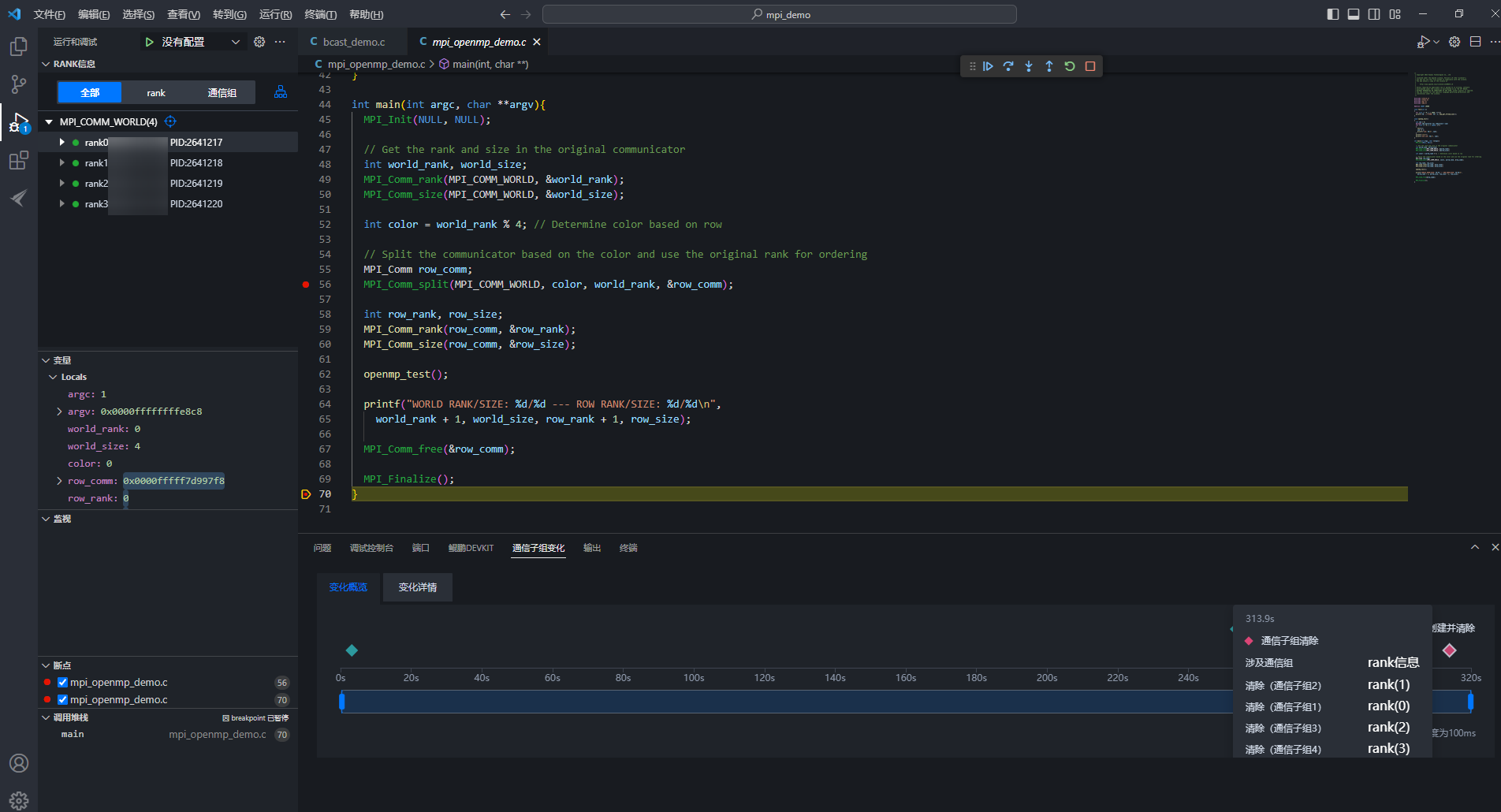
- 在左侧调试区域查看调试信息。图18 查看调试信息