示例2:列访问循环检测优化
简介
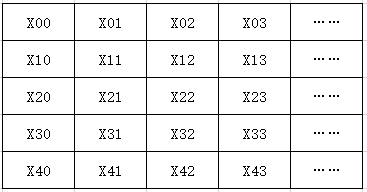
针对上述二维数组,在内存中是按行顺序排列的,即:X00、X01、X02、X03、……、X10、X11、X12、X13……处理器从内存获取数据时,会获取该数据及其它附近共64字节(Cache Line长度)的数据,例如获取X00,实际也会读取X00后面的X01、X02……这样接下来处理器要读取X01的数据时,它就不需要再访问内存了,而直接从Cache中就能获取到。所以,程序按行顺序读取数据,节省了访存的时间,性能就很高。如果按列读取,读取X00时缓存的数据中可能并不包含X10,所以接下来访问X10时,访问缓存失败,又需要访问内存。
本示例基于二维数组循环遍历程序,采用访存分析,分析结果显示按行访问可以优化CPU Cache命中效率。
环境准备
Cache_miss数组访问工具检测
- 程序准备。
- 编译cache_miss.c并赋予执行文件所有用户可读、可写和可执行权限。
gcc -g cache_miss.c -o cache_miss && chmod 777 cache_miss
- 将cache_miss测试程序绑定CPU核并使用后台启动脚本miss_start.sh 启动程序,使得程序循环运行多次,以便有时间运行系统级别的采集任务,nohup命令使得即使退出账户之后会继续运行相应的进程,防止任务中断。
nohup bash miss_start.sh >>cache_miss.out 2>&1 &
程序运行的输出标准输出(1)将会保存到cache_miss.out文件,错误信息(2)会重定向到cache_miss.out文件。
其中miss_start.sh脚本内容如下,如果miss_start.sh程序没有正常运行,可以通过cache_miss.out文件检查错误信息,注意检查是否为window-style line endings问题,如果是window-style line endings问题,可以通过vi -b miss_start.sh进行删除。
图1 脚本内容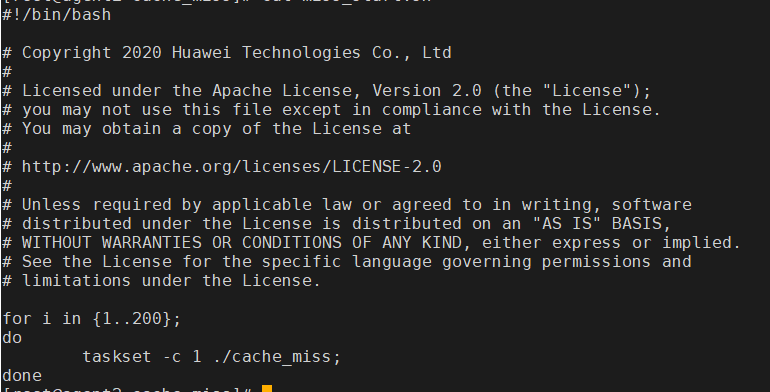
- 编译cache_miss.c并赋予执行文件所有用户可读、可写和可执行权限。
- 在程序运行的过程当中,创建系统的全景分析任务,分析当前程序。
创建系统全景分析任务,并启动分析。
表1 任务配置参数说明 参数
说明
分析对象
系统
分析类型
全景分析
采样类型
全选
采样时长
20秒
采样间隔
1秒
- 查看采集分析结果。
“系统性能”页签的图2可以看到图形化界面的CPU核在采集时间内的利用率变化,可以看到在采集时间内的各项数据的平均值。
- 采用进程/线程性能分析,查看消耗CPU资源的进程。
创建进程/线程性能分析任务,并启动分析。
表2 任务配置参数说明 参数
说明
分析对象
系统
分析类型
进程/线程性能分析
采样时长
10秒
采样间隔
1秒
采样类型
全选
采集线程信息
开启
- 查看采集分析结果。
图3默认排序是按照PID/TID升序排列,为便于查看消耗CPU资源的进程,可点击%CPU列旁边的
 按钮进行降序排列。
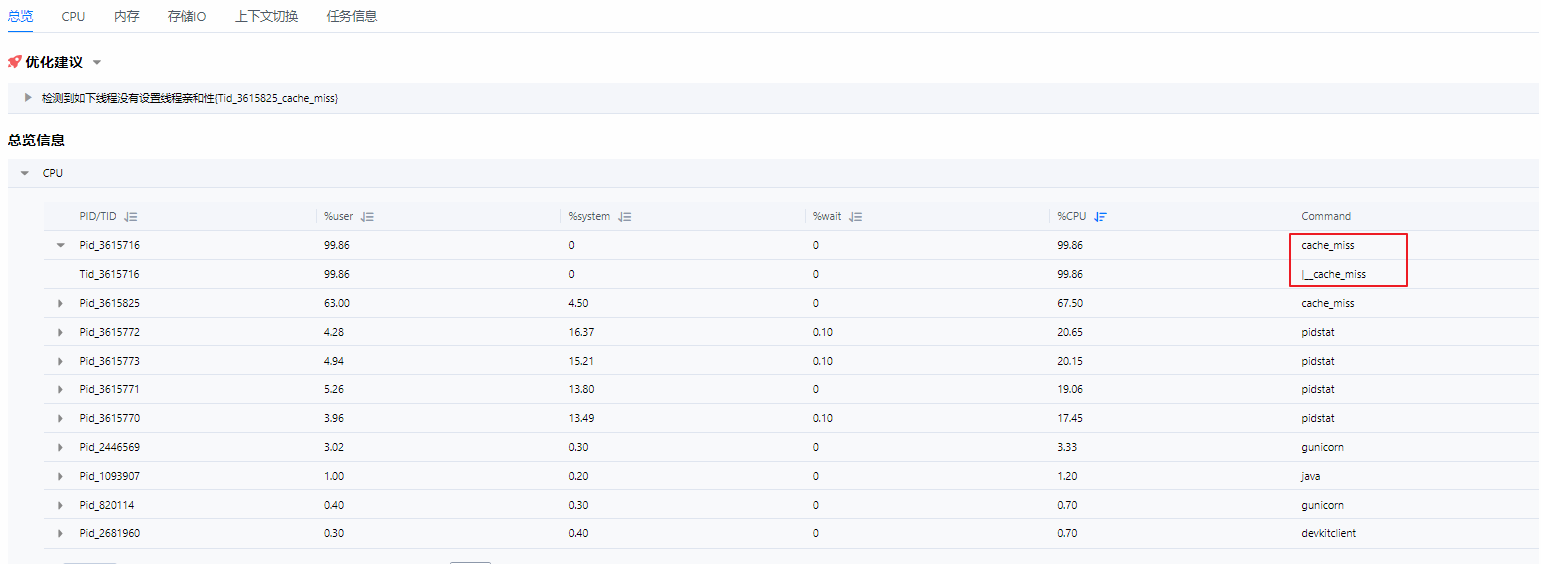
按钮进行降序排列。可以看到cache_miss程序在消耗大量的CPU,同时全部消耗在用户态中,可推测是代码实现算法差或Cache Miss问题。
- 结束样例程序。
通过jobs -l查看cache_miss程序运行pid(如果程序尚未结束,可以看到后台运行的程序),通过kill -9结束进程。
jobs -l kill -9 <cache_miss程序pid>
- 采用热点函数分析cache_miss程序,找到热点函数和指令。
创建热点函数分析任务,并启动分析。
表3 任务参数配置说明 参数
说明
分析对象
应用。本示例分析的热点函数为已确定程序,所以不需在服务器上运行程序,直接在工具中选择cache_miss程序。
模式
Launch application
应用路径
输入程序所在的绝对路径,例如本示例将代码样例放在服务器“/opt/testdemo/cache/cache_miss/cache_miss”目录下。示例路径里面第一个cache_miss为文件夹,第二个cache_miss为可执行程序。
分析类型
热点函数分析
采样范围
用户态。采样范围分用户态、内核态、所有。因为发现所有的CPU消耗都在用户态,所以只采集用户态的数据。
采集调用栈
开启。
dwarf
开启。
C/C++ 源文件目录
用于采集过程时关联源码。本示例使用/opt/testdemo/cache/cache_miss/。
其他参数
默认
- 查看采集分析结果。图4 热点函数分析结果总览
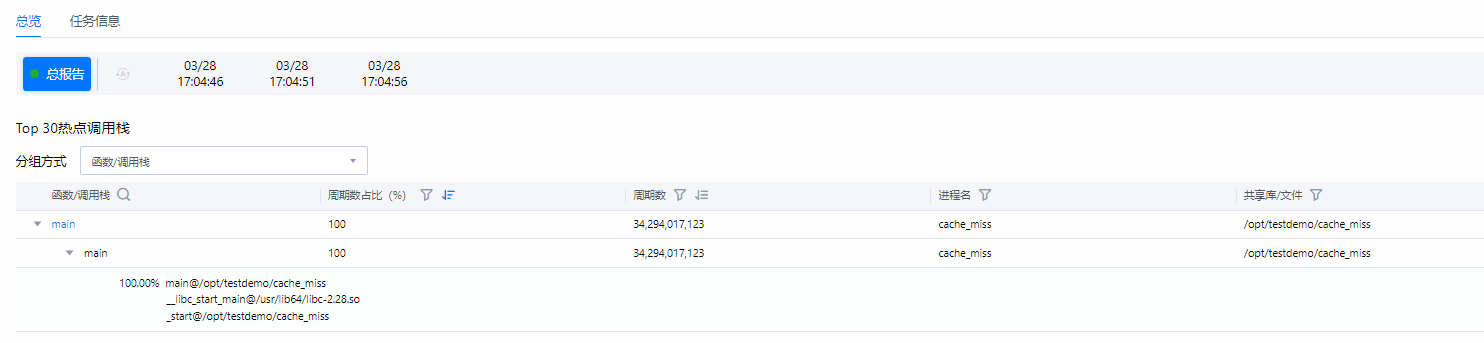
在下面的热点函数中,可以看到cache_miss程序中的main函数所占用了所有的时钟周期数;单击蓝色函数名,可查看源码对应行数。
- 采用,进一步确认是Cache Miss造成。

如果服务器操作系统不是openEuler,则这一步无法执行。
表4 任务参数配置说明 参数
说明
分析对象
应用。在之前步骤已经确定大量消耗CPU资源的程序,所以可直接分析对应程序的性能问题。
模式
Launch application
应用路径
输入程序所在的绝对路径,例如本示例将代码样例放在服务器/opt/testdemo/cache/cache_miss/cache_miss目录下。示例路径里面第一个cache_miss为文件夹,第二个cache_miss为可执行程序。
分析类型
访存分析
访存分析类型
Miss事件分析
采样时长
5秒
采样间隔(指令数)
8192
其他参数
默认
- 查看采集分析结果。图5 Miss事件分析结果(时序视图)
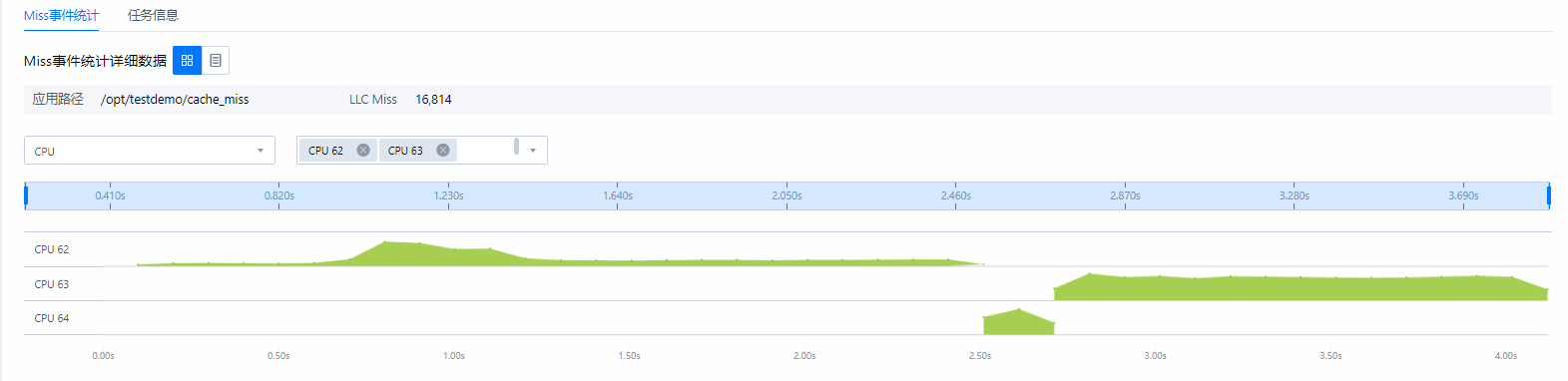
在“时序视图”页签下,第一个下拉菜单中有四个选项:进程、线程、模块、CPU,可选择不同模块,然后可以看到程序cache_miss在采集时间内实时的Miss事件的次数。

优化方案
- 程序准备。
编译cache_hit.c并赋予执行文件所有用户可读、可写、可执行权限。
gcc -g cache_hit.c -o cache_hit && chmod 777 cache_hit
- 采用热点函数分析功能进行分析。创建热点函数分析任务,并启动分析。
表5 任务参数配置说明 参数
说明
分析对象
应用。
模式
Launch application。
应用路径
输入程序所在的绝对路径,例如本示例将代码样例放在服务器“/opt/testdemo/cache/cache_hit/cache_hit”目录下。示例路径里面第一个cache_hit为文件夹,第二个cache_hit为可执行程序。
分析类型
热点函数分析。
采样范围
用户态。采样范围分用户态、内核态、所有。因为发现所有的CPU消耗都在用户态,所以只采集用户态的数据。
采样时长(s)
30秒。
采集调用栈
开启。
dwarf
开启。
C/C++ 源文件目录
用于采集过程时关联源码。本示例使用/opt/testdemo/cache/cache_hit/。
其他参数
默认。
- 查看采集分析结果。图6 热点函数分析结果总览
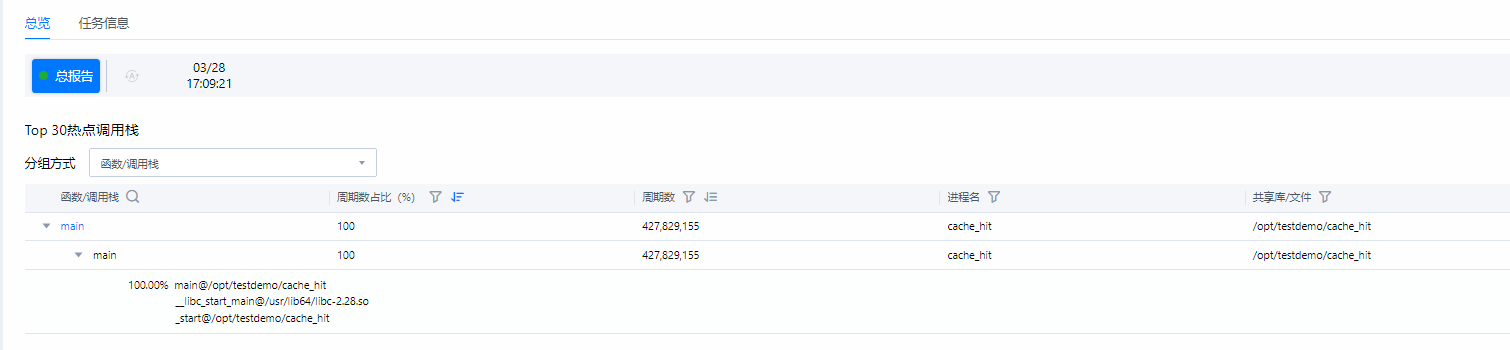
比较cache_hit和cache_miss程序的热点函数分析结果,优化后的程序运行时间和周期数远远小于未优化前的。
此处数值根据sampling采集数据得来,非绝对值,不同环境的数值可能有较大差别,主要关注优化前后的变化。
- 采用功能进一步分析。
创建访存分析任务,并启动分析。
表6 任务参数配置说明 参数
说明
分析对象
应用。在之前步骤已经确定大量消耗CPU资源的程序,所以可直接分析对应程序的性能问题。
模式
Launch application
应用路径
输入程序所在的绝对路径,例如本示例将代码样例放在服务器“/opt/testdemo/cache/cache_hit”目录下。
分析类型
访存分析
访存分析类型
Miss事件分析
采样时长
5秒
采样间隔(指令数)
8192
其他参数
默认
- 查看采集分析结果。图7 Miss事件分析结果(时序视图)
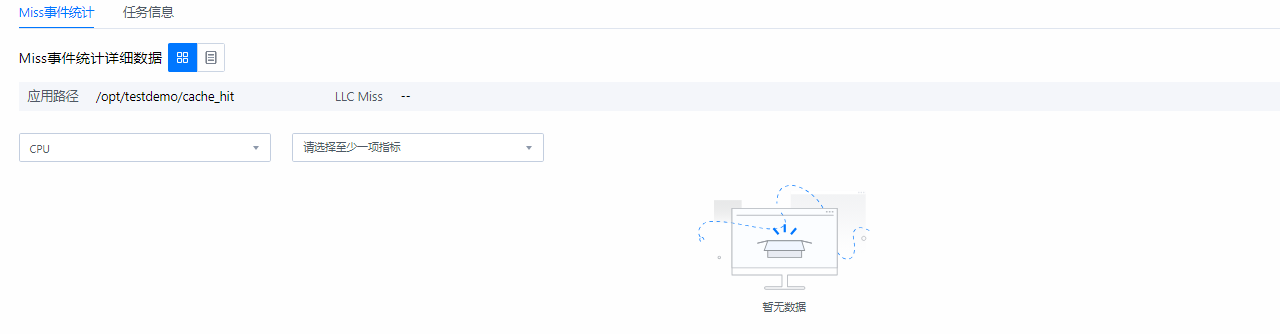
优化后,没有采集到Miss事件。
结果分析
优化循环体后的cache_hit函数执行时间明显降低,Miss的数目大幅减少。