矩阵转置&block&vector示例
对于之前并行示例到矩阵转置&block示例运行时间进行优化。
调优思路
图1 SIMD指令集
图2 矩阵转置&block&vector代码 1

图3 矩阵转置&block&vector代码 2

在保证cacheline对齐寻址的情况下,对矩阵B进行转置,并选择合适block size进行向量化指令优化。
操作步骤
- 运行intrinsics_transpose_B_matmult示例。
./matmul 8192 5
返回信息如下:
Size is 8192, Matrix multiplication method is: 5, Check correctness is: 0 Initialization time = 2.787161s Matrix multiplication time = 2.600979s
矩阵行列大小为8192情况下,并行计算耗时2.6秒左右。
- 创建intrinsics_transpose_B_matmult的Roofline任务。
使用命令行工具进行roofline任务分析。
devkit tuner roofline -o intrinsics_transpose_B_matmult_8192 -m region ./matmul 8192 5
返回信息如下:
Note: 1. Roofline task is currently only supported on the 920 platform. 2. The application must be a binary file in ELF format. 3. Roofline task collection needs to ensure the application has finished running. 4. The estimated time of roofline collection is about 3 * application estimated time. 5. You can learn about the roofline profiling method by looking at document /usr/local/devkit/tuner/docs/ROOFLINE_KNOW_HOW.MD RFCOLLECT: Start collection for ./matmul RFCOLLECT: Launch application to collect performance metrics of ./matmul Size is 8192, Matrix multiplication method is: 5, Check correctness is: 0 Initialization time = 2.751606s ROOFLINE_EVENTS are initialized. Matrix multiplication time = 2.741322s RFCOLLECT: Launch application to do binary instrumentation of ./matmul Size is 8192, Matrix multiplication method is: 5, Check correctness is: 0 Initialization time = 8.353003s Matrix multiplication time = 2.519457s RFCOLLECT: Launch benchmarks for measuring roofs RFCOLLECT: Processing all collected data RFCOLLECT: Result is captured at /matrix_multiplication/rfcollect-20240506-201408.json RFCOLLECT: Run "rfreport /matrix_multiplication/rfcollect-20240506-201408.json" to get report. Get roofline report ... The roofline json report: /matrix_multiplication/intrinsics_transpose_B_matmult_8192.json The roofline html report: /matrix_multiplication/intrinsics_transpose_B_matmult_8192.html
- 查看intrinsics_transpose_B_matmult_8192报告。图4 intrinsics_transpose_B_matmult_8192报告
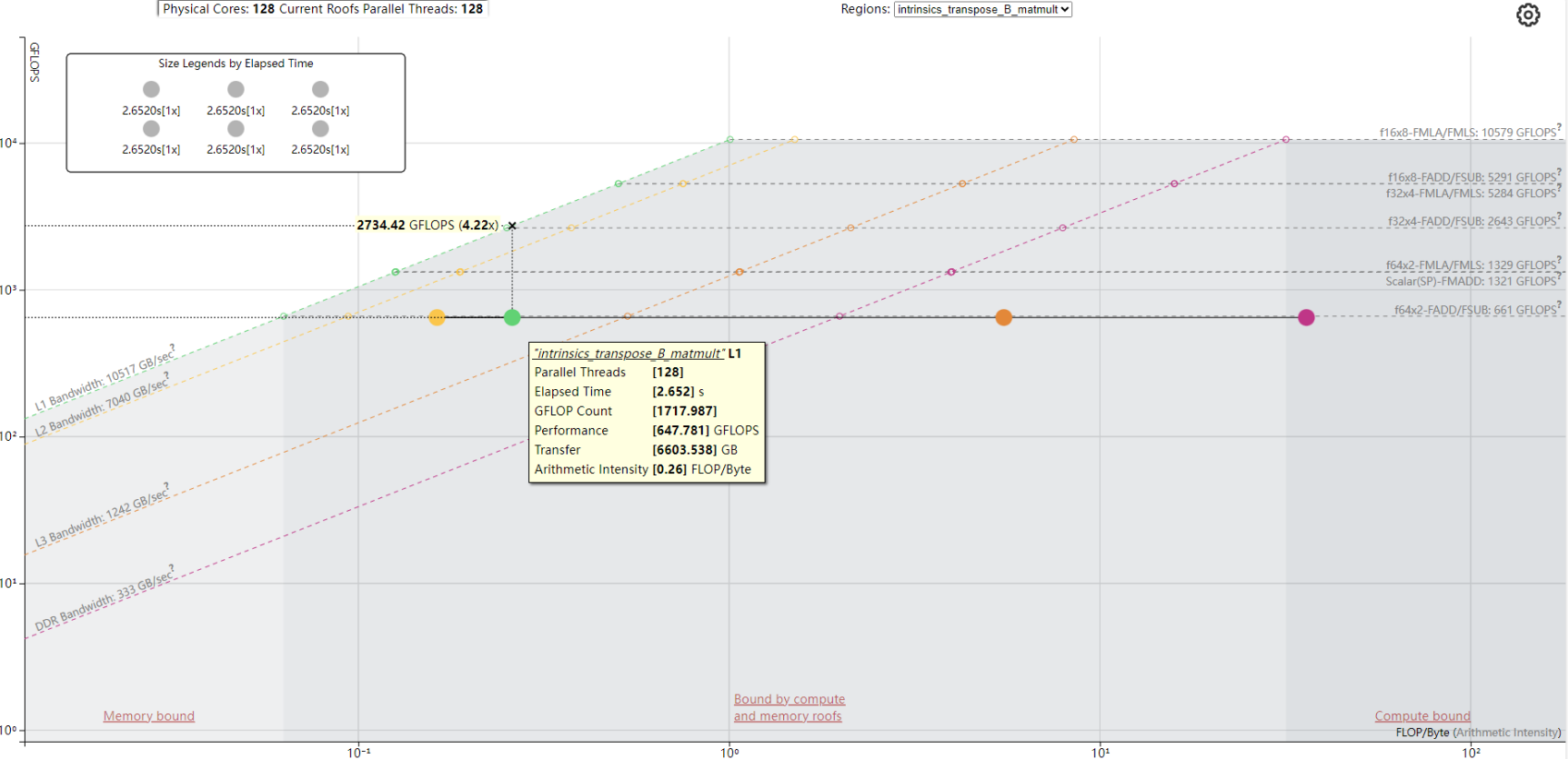
此时获取的roofs的并行度为128,获取到Elapsed Time 2.664s,GFLOP Count 1717.987,Performance 647.781 GFLOPS。
优化效果
使用intrinsics向量化指令后,计算方式发生很大的变化,计算量有47.1%的增加(从1168.231GFLOP到1717.987GFLOP),同时向量化指令也有更大的性能提升,因此端到端性能有了大幅提升,详见下表。
case |
Elapsed Time(s) |
GFLOP Count |
Performance |
单位时间性能倍率(相比于前一case) |
端到端性能倍率(相比于前一case) |
单位时间性能倍率(相比于基准case) |
端到端性能倍率(相比于基准case) |
|---|---|---|---|---|---|---|---|
parallel_matmult_8192 |
516.824 |
1099.512 |
2.127 |
-- |
-- |
-- |
-- |
transpose_B_matmult_8192 |
10.017 |
1099.512 |
109.763 |
51.595 |
51.595 |
51.595 |
51.595 |
block_transpose_B_matmult_8192 |
3.646 |
1168.231 |
320.399 |
2.919 |
2.747 |
150.634 |
141.751 |
intrinsics_transpose_B_matmult_8192 |
2.664 |
1717.987 |
647.781 |
2.013 |
1.369 |
303.181 |
194.003 |
图5 对比分析
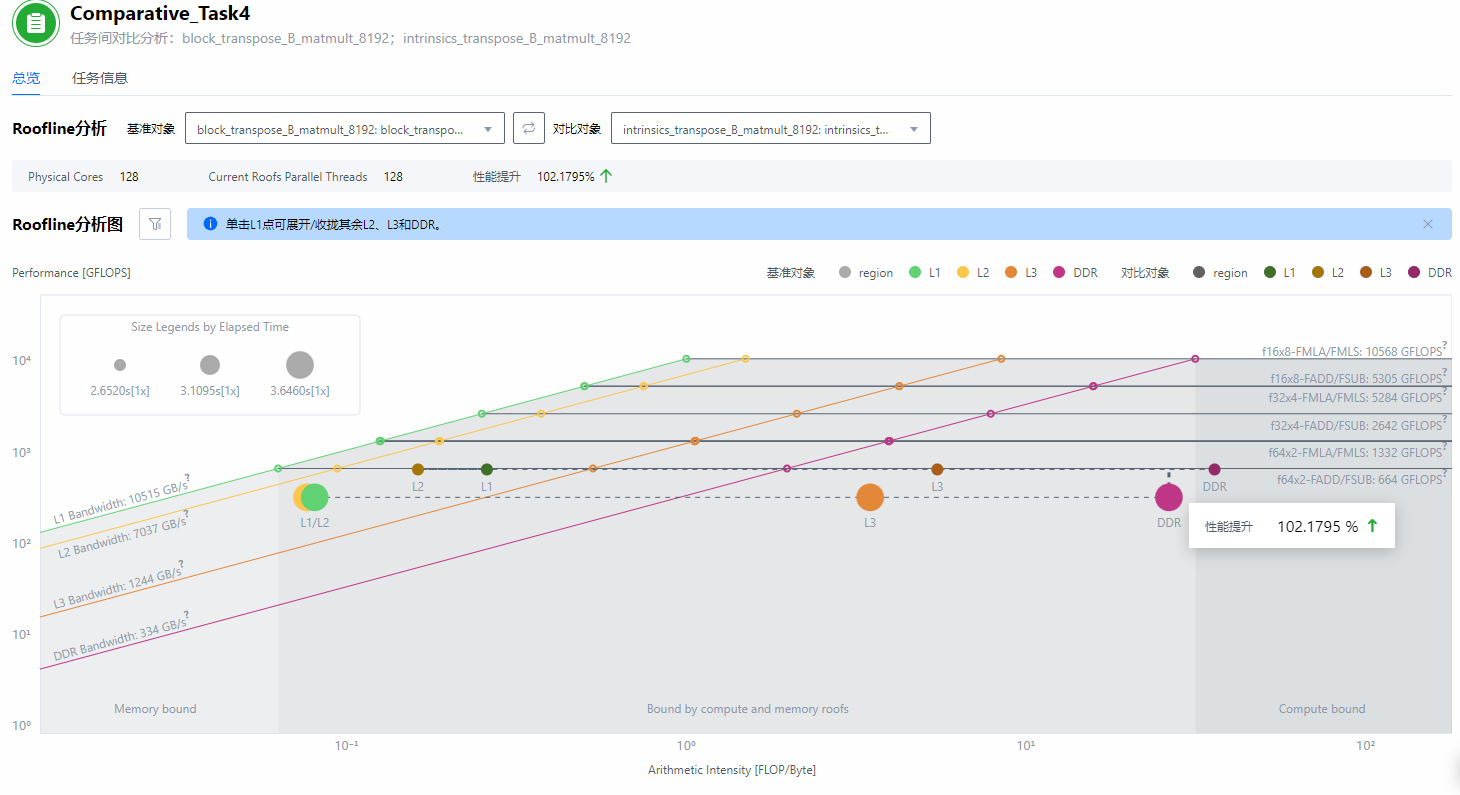
对比block_transpose_B_matmult 8192与intrinsics_transpose_B_matmult 8192。
- Going UP:Performance提升了1倍左右,实际的端到端性能优化倍率为1.37倍左右。
- Going RIGHT:较少的右移, 使用向量化指令让计算变得更快,计算密度FLOP/Byte没有发生太大的变化(预期中)。
父主题: 使用Roofline进行性能分析