查看进程/线程性能分析结果
前提条件
已创建调优分析任务并完成分析。
操作步骤
- 在左侧“调优助手”区域,单击指定分析任务名称前的
 ,展开节点列表。
,展开节点列表。 - 单击节点名称,打开分析结果页面查看分析结果。图1 分析结果页面

- (可选)选择业务类型和建议类型。
- 根据实际情况选择业务类型。可选类型包括:CPU密集型、网络IO密集型和存储IO密集型。可以选择1~3个业务类型,默认三个选项均被选中。
图2 选择业务类型

- 根据实际情况选择建议类型。可以调节优化建议拓扑树显示“调优路径建议”或“经过阈值过滤的建议”。
图3 选择建议范围

- 根据实际情况选择业务类型。可选类型包括:CPU密集型、网络IO密集型和存储IO密集型。可以选择1~3个业务类型,默认三个选项均被选中。
- 单击“进程/线程性能”,查看进程/线程性能分析结果,可进行调优设置。图4 进程/线程性能页面

在“进程/线程性能”分析结果页面,可以进行以下操作。
- 在“CPU指标”下拉选择框中选择要查看的CPU指标,表1描述了可选的CPU指标。
- 单击
 设置利用率区间。
在弹出“利用率区间”对话框中设置CPU利用率Normal范围的起始值和结束值,然后单击“确认”。图5 设置利用率区间
设置利用率区间。
在弹出“利用率区间”对话框中设置CPU利用率Normal范围的起始值和结束值,然后单击“确认”。图5 设置利用率区间
- 把鼠标悬停在一个方块上,查看该CPU核的各项性能数据。单击“查看相关线程”可查看CPU核的相关线程(线程用三角形表示)。在线程视图中,可单击左上角的PID返回
图6 悬停查看CPU核性能数据
 图6 查看相关线程
图6 查看相关线程
- 单击一个方块,在右边详情区域查看该CPU核的详细进程和线程信息,若为nginx相关线程,还包括微架构指标、访存指标、CPU亲和性、内存亲和性、操作的函数、操作的文件、操作的网口和操作的系统调用信息。
图8 查看CPU核进程/线程详情


可单击
 展开详情区域,默认不展开。
展开详情区域,默认不展开。可单击
 收缩CPU指标区域,默认展开。
收缩CPU指标区域,默认展开。
- 查看状态为Busy的CPU核的进程/线程性能优化建议拓扑树图。
- 当CPU指标设置为%user且有状态为Busy的CPU核时,页面右边可设置相关参数的阈值并查看详情,页面下方为进程/线程性能优化建议拓扑树图。
图9 进程/线程性能优化建议拓扑树(%user)

表2描述了阈值设置区域的参数。
表2 阈值设置区域参数说明 参数
描述
cpu亲和性
CPU亲和性配置,是一种调度属性,它可以将一个进程“绑定”到一个或一组CPU上。
内存亲和性
内存亲和性配置,是一种调度属性,它可以将内存分配给本地NUMA节点上。
并发数
进程中线程的数量。
branch miss rate (%)
CPU运行指令分支缺失率。取值为1~100的正整数。
L1-dcache miss rate (%)
L1数据缓存缺失率。取值为1~100的正整数。
L1-icache miss rate (%)
L1指令缓存缺失率。取值为1~100的正整数。
dTLB cache miss rate (%)
数据TLB缓存缺失率。取值为1~100的正整数。
iTLB cache miss rate (%)
指令TLB缓存缺失率。取值为1~100的正整数。
fault/s
每秒系统产生的缺页数。取值为任意正整数。
表3描述了进程/线程性能优化建议拓扑树图上的主要节点。
表3 进程/线程性能优化建议拓扑树图一级节点 节点
描述
进程及其线程存在在不同NUMA NODE间切换
一个进程在执行的过程中,在不同的NUMA NODE上进行切换。
进程/线程跨DIE或跨片访问内存
cpu跨片/跨DIE访问内存比例高。
并发度:并发度少
进程的线程数小于6。
Branch:Branch Miss高
指令运行分支缺失次数较多
Cache:Cache Miss高
当运算器需要从存储器中提取数据时,它首先在最高级的Cache中寻找然后在次高级的Cache中寻找。如果在Cache中找到,则称为命中hit;反之,则称为不命中miss。
TLB:TLB Miss高
当需要访问的虚拟内存,不在TLB当中时,称之它为TLB Miss。
内存:page fault高
内存产生的缺页数高。
JVM:JVM消耗CPU高
JVM消耗的CPU资源过高。
编译:编译器及编译选项
编译器及编译的选项。
采用访存分析功能分析
分析内存的访存相关能力。
热点函数分析:分析TOP热点函数
分析系统或进程的热点函数。
针对表3中列出的每个问题,可以单击节点查看问题详情并单击下一级节点查看对应的优化建议。
- 当CPU指标设置为%sys且有状态为Busy的CPU核时,页面右边可设置相关参数的阈值并查看详情,页面下方为进程/线程性能优化建议拓扑树图。
图10 进程/线程性能优化建议拓扑树(%sys)

表4描述了阈值设置区域的参数。
表4 阈值设置区域参数说明 参数
描述
应用上下文切换
上下文切换指的是内核(操作系统的核心)在CPU上对进程或者线程进行切换。
应用系统调用总的系统CPU时间(ms)
一次系统调用的过程,其实是发生了两次CPU上下文切换(用户态-内核态-用户态)。
进程majflt/s
每秒钟产生的主缺页数。
应用内存消耗(%)
内存占用高,占比超过30%。
表5描述了进程/线程性能优化建议拓扑树图上的主要节点。
表5 进程/线程性能优化建议拓扑树图一级节点 节点
描述
调度开销:上下文切换次数高
上下文切换次数过多,会导致耗费大量CPU资源,降低性能。
SWAP:majflt/s高
每秒钟产生的主缺页数过高。
热点函数分析:分析TOP热点函数
分析系统或进程的热点函数。
针对表5中列出的每个问题,可以单击节点查看问题详情并单击下一级节点查看对应的优化建议。
- 当CPU指标设置为%cpu且有状态为Busy的CPU核时,页面右边可设置相关参数的阈值并查看详情,页面下方为进程/线程性能优化建议拓扑树图。
图11 进程/线程性能优化建议拓扑树(%cpu)

表6描述了阈值设置区域的参数。
表6 阈值设置区域参数说明 参数
描述
应用系统阻塞函数调用次数
应用每秒调用系统阻塞函数的次数。
网络收发吞吐量
单位时间内通过某个网络(或信道、接口)的数据量。
应用每秒读大小
进程每秒从硬盘读取的数据量。
应用每秒写大小
进程每秒向硬盘写入的数据量。
应用IO延迟
块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
rngd服务
rngd服务用来检查是否有充分随机的随机性源来提供数据并存储它到内核的随机数熵池。
表7描述了进程/线程性能优化建议拓扑树图上的主要节点。
表7 进程/线程性能优化建议拓扑树图一级节点 节点
描述
网络IO:网络收发吞吐量和收发数量低
网络收发吞吐量和收发数量低。
任务阻塞:采用锁与等待分析功能分析
进入系统性能分析,采用锁与等待分析,确定性能瓶颈。
存储IO:进程读写存储量大或延时高
进程读写存储量大或延时高。
系统使用rngd服务
rngd服务用来检查是否有充分随机的随机性源来提供数据并存储它到内核的随机数熵池。
针对表7中列出的每个问题,可以单击节点查看问题详情并单击下一级节点查看对应的优化建议。
- 当CPU指标设置为%user且有状态为Busy的CPU核时,页面右边可设置相关参数的阈值并查看详情,页面下方为进程/线程性能优化建议拓扑树图。
- 根据优化建议拓扑树,可进行调优设置。
- 查看分析结果页面的优化建议拓扑树图,根据配置条件
 ,单击
,单击 选择对应的调优建议。
图12 优化建议拓扑树图
选择对应的调优建议。
图12 优化建议拓扑树图
- 查看右侧调优建议中的相关配置、指标说明、优化建议及优化指导。单击
 确定采纳该调优建议,单击
确定采纳该调优建议,单击 取消采纳该调优建议。
图13 调优建议页面
取消采纳该调优建议。
图13 调优建议页面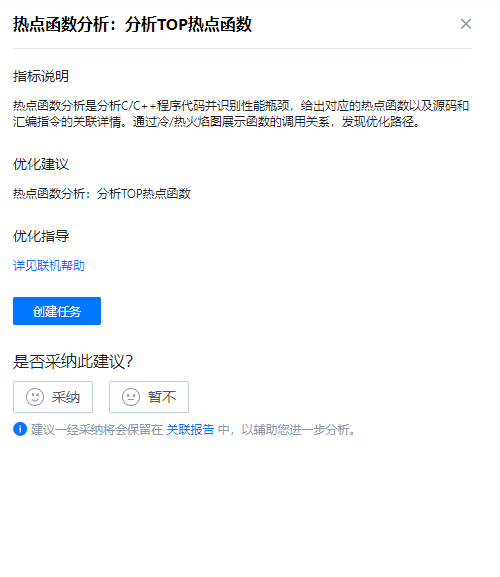
- 已采纳的调优建议将会保留在关联报告中,单击页面右下角“关联报告”进入关联报告页面。
关联报告页面会显示已经采纳的所有调优建议,单击任务名称可进行查看。根据采纳的调优建议是否达到预期目标,单击左下角“有效”和“无效”进行确定。
图14 关联报告页面
- 查看分析结果页面的优化建议拓扑树图,根据配置条件
- 单击“进程线程性能”分析结果界面右侧的
 查看进程/线程性能详细数据。图15 查看进程/线程性能详细数据
查看进程/线程性能详细数据。图15 查看进程/线程性能详细数据