Word2Vec
用例编号 |
4.2.23 |
|---|---|
测试目的 |
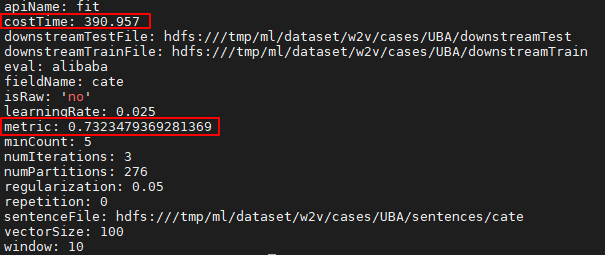
Word2Vec(词向量)性能测试 |
测试组网 |
测试组网如图1所示。 |
预置条件 |
|
测试步骤 |
|
预期结果 |
|
测试结果 |
|
备注 |
|


父主题: 机器学习算法测试