软件预取
原理
数据预取通过将代码中后续可能使用到的数据提前加载到Cache中,减少CPU等待数据从内存中加载的时间,提升Cache命中率,进而提升软件的运行效率。预取指令格式通常如下:
1 | PRFM prfop, [Xn|SP{, #pimm}] |
- prfop由type、<target>、<policy>三部分组成。
- type可选模式如下。
- PLD:数据预加载
- PLI:指令预取
- PST:数据预存储
- <target>可选模式如下。
- L1
- L2
- L3
L1、L2、L3分别表示对三个不同的Cache层级进行操作。
- <policy>可选模式如下。
- KEEP:数据预取使用后保存一定时间,适用于数据多次使用的场景。
- STRM:流式或非临时预取,数据使用后将淘汰,用于仅使用一次的数据。
- type可选模式如下。
- Xn|SP通常表示64位通用寄存器或栈指针,使用场景中通常为预取的起始地址。
- pimm是以字节为单位的偏移量,代表预取的字节长度,取值为8的整数倍,范围是0~32760,默认为0。预取长度可结合实际业务场景设定,尝试预取不同长度数据,获取最佳预取值。
从指令组成看,预取指令中核心部分为prfop,其决定了预取的类型、预取Cache层级以及预取的数据使用模式。本小节主要说明PLD数据预取,其他模式类似。数据预取核心指令部分如下表 数据预取核心指令所示:
数据预取指令 |
指令功能说明 |
|---|---|
PLDL1KEEP |
数据预取到L1 Cache,策略为KEEP模式,数据使用后常驻Cache |
PLDL2KEEP |
数据预取到L2 Cache,策略为KEEP模式,数据使用后常驻Cache |
PLDL3KEEP |
数据预取到L3 Cache,策略为KEEP模式,数据使用后常驻Cache |
PLDL1STRM |
数据预取到L1 Cache,策略为STRM模式,数据使用后从Cache淘汰 |
PLDL2STRM |
数据预取到L2 Cache,策略为STRM模式,数据使用后从Cache淘汰 |
PLDL3STRM |
数据预取到L3 Cache,策略为STRM模式,数据使用后从Cache淘汰 |
GCC编译器针对预取也有对应的builtin函数实现,格式如下:
1 | __builtin_prefetch (const void *addr, int rw, int locality) |
- addr:数据的内存地址。
- rw:可选参数。rw可设置为0或1,0表示读操作,1表示写操作。
- locality:可选参数。locality可设置0-3(默认为3),表示数据在Cache中保持的时间,即时效性。取值为0表示访问的数据后续不再被访问,使用后在Cache中淘汰;取值为3表示访问的数据将再次访问;取值为1和2,则分别表示具有低时效性和中时效性。
更多关于预取指令的描述可参考ARM指令集手册:
https://developer.arm.com/documentation/ddi0596/2021-06/Base-Instructions/PRFM--immediate---Prefetch-Memory--immediate--?lang=en
修改方式
// 从ptr处预读取128字节数据
void inline Prefetch(int *ptr)
{
__asm__ volatile("prfm PLDL1KEEP, [%0, #(%1)]"::"r"(ptr), "i"(128));
}
PLDL1KEEP指令组成如下:
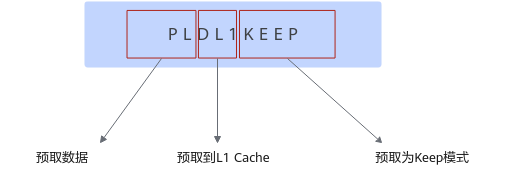
PLDL1KEEP表示将数据预取到L1 Cache中,策略为KEEP模式。数据使用完后,将保留一定时间,适用于数据多次使用的场景。
以下示例代码功能为两数组对应元素相乘,通过每次预取多个数据,并将循环展开来对预取数据进行使用,提升计算性能,代码如下。
for (int i = 0; i < ARRAYLEN; i++) {
arrayC[i] = arrayA[i] * arrayB[i];
}
添加预取:
int i;
Prefetch(&arrayA[0]);
Prefetch(&arrayB[0]);
for (i = 0; i < ARRAYLEN - ARRAYLEN % 4; i+=4) {
Prefetch(&arrayA[i + 4]);
Prefetch(&arrayB[i + 4]);
arrayC[i] = arrayA[i] * arrayB[i];
arrayC[i + 1] = arrayA[i + 1] * arrayB[i + 1];
arrayC[i + 2] = arrayA[i + 2] * arrayB[i + 2];
arrayC[i + 3] = arrayA[i + 3] * arrayB[i + 3];
}
for (; i < ARRAYLEN; i++) {
arrayC[i] = arrayA[i] * arrayB[i];
}
通过测试耗时分别为:使用预取耗时5569us,不使用预取耗时9359us,优化后代码性能显著提升。