NEON指令加速
NEON是一种基于SIMD思想的技术,能够基于单条指令对多个数据同时进行操作,其使用的
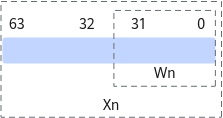
NEON技术依赖于128位NEON寄存器的硬件支持,NEON寄存器是一种向量寄存器,一个寄存器中可存储多个数据元素,但要求其具有相同的数据类型。
以下是ARMv8-A中AArch64架构下的寄存器:
使用编译器能力自动向量化加速
原理:
编译器支持自动向量化功能,其会自动利用NEON属性,编译时将代码向量化。启用自动向量化功能前需要打开相应的编译选项,且并非所有代码均可向量化,其需要符合一定的编码方式和规律,以提供更多的提示信息给编译器,进一步触发编译器进行代码的向量化。
支持该特性的编译器有:GCC、LLVM、适用于嵌入式和Linux项目的ARM编译器。
修改方式:
- 自动向量化编译选项使能
- GCC编译器使用-O3会自动使能-ftree-vectorize选项,在-O1和-O2下需要添加-ftree-vectorize选项才能进行向量化。在-O0模式下,即使添加-ftree-vectorize也无法进行向量化。
- armcc编译器使用-vectorize选项来使能向量化编译,一般选择更高的优化等级如-O2或者-O3就能使能-vectorize选项。在-O1模式下需要使用-vectorize选项使能向量化编译,在-O0模式下,即使添加-vectorize选项编译器同样无法进行向量化。
在Armv8-a的AArch64架构下才支持双浮点计算的向量化,其他架构下非必需时避免使用双浮点的数据类型,该类型会阻止编译器做向量化。各架构下支持的数据类型如下:
-
Armv7-A/R
Armv8-A/R
Armv8-A
-
-
AArch32
AArch64
Floating-point
32-bit
16-bit/32-bit
16-bit/32-bit/64-bit
Integer
8-bit/16-bit/32-bit
8-bit/16-bit/32-bit/64-bit
8-bit/16-bit/32-bit/64-bit
arch命令下可查看CPU硬件架构是AArch64还是AArch32。
- 编码方式上触发代码向量化
- 循环次数在已知时要直接传递常数,而不使用变量,让编译器预先明确循环迭代次数。循环次数是2的指数倍时,需告知编译器,以便尽可能地向量化。在循环次数非2的指数倍时,也可将循环分解进行构造。
void vecAdd(int *vecA, int *vecB, int *vecC, int len) { int i; // 告诉编译器len是4的整数倍 for (i = 0; i < len * 4; i++) { vecC[i] = vecA[i] + vecB[i]; } } - 在控制循环结束的条件中,尽量使用 "<"来进行条件判断,而不使用"<="或"!=",使用 "<"能使编译器识别到在该变量值之前循环结束,这有助于编译器进行向量化。
- 使用restrict关键字
为指针添加__restrict或__restrict__关键字,提示编译器,对象已经被指针所引用,不能通过除该指针外所有其他直接或间接的方式修改该对象的内容,编译器以此获知当前对象无其他依赖,可并行操作和向量化。但使用前必须确保确实没有指针访问区域重叠的现象,否则计算结果可能会出错。
void vecAdd(int *__restrict__ vecA, int *__restrict__ vecB, int *__restrict__ vecC, int len) { int i; for (i = 0; i < len *4; i++) { vecC[i] = vecA[i] + vecB[i]; } } - 避免循环依赖(即某次循环的结果会被前一次循环的结果影响)。
- 在满足需求情况下,使用较小的数据类型,以便向量化后,NEON寄存器一次能处理更多数据,提升向量化后代码性能。
- 避免在循环中出现条件判断,尽量少用break跳出循环。
- 编写简单的代码,编译器更容易理解与自动向量优化。(向量化程度取决于编译器所理解编码人员代码意图的程度。)
- 用数组下标来替代指针访问元素。
- 构造结构体时,可尽量保持结构体内变量的数据类型一致,便于数据加载时向量化。
如下为像素点数据结构体做4字节对齐,采用以下方式可进行向量化:
struct aligned_pixel { char r; char g; char b; char not_used; /* Padding used to keep r aligned to a 32-bit word */ }screen[10];若只改变结构体内单个元素变量类型进行数据对齐,导致结构体内变量数据类型不同,则无法进行自动向量化:
struct pixel { char r; short g; /* Green channel contains more information */ char b; }screen[10];
- 循环次数在已知时要直接传递常数,而不使用变量,让编译器预先明确循环迭代次数。循环次数是2的指数倍时,需告知编译器,以便尽可能地向量化。在循环次数非2的指数倍时,也可将循环分解进行构造。
使用NEON Intrinsic加速提升性能
原理:
NEON Intrinsic函数是一系列C函数调用,编译器可将其替换为适当的NEON指令或NEON指令序列。NEON Intrinsic函数几乎提供与编写NEON汇编指令相同的功能,但是将寄存器分配等工作留给编译器,以便开发人员可以专注于算法开发。与使用NEON汇编指令编码相比,NEON Intrinsic方式的代码有更好的可维护性。ARM编译器、GCC和LLVM编译器都支持NEON Intrinsic。
修改方式:
在使用NEON Intrinsic函数时需要增加头文件#include <arm_neon.h>,详细的NEON Intrinsic函数列表和使用方法,可参考NEON Intrinsic Reference:https://developer.arm.com/architectures/instruction-sets/simd-isas/neon/intrinsics