重启Ceph集群的OSD进程失败的解决方法
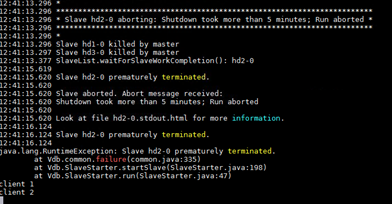
问题现象描述
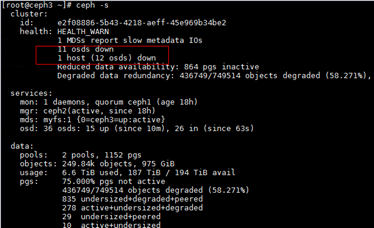
关键过程、根本原因分析
“osd_memory_target”的值不是官方发布的默认的4G。
结论、解决方案及效果
- 查看Ceph日志时发现往Ceph分配内存时失败,怀疑在OSD进程在获取内存时有异常。
- 输入以下命令发现“osd_memory_target”的值并非官方发布的默认的4G。
ceph --admin-daemon /var/run/ceph/ceph-osd.0.asoc config show | grep memory

- 在ceph.conf文件中添加“osd_memory_target = 4294967296”,使分配给每个OSD的内存限制为4GB。
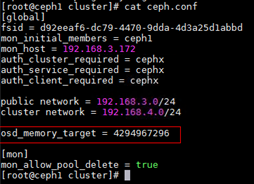
- 将修改后的文件推送到其他节点。
ceph-deploy --overwrite-conf admin ceph1 ceph2 ceph3 client1 client2 client3
- 重启集群。
systemctl restart ceph.target