代码迁移—SSE Intrinsic函数移植
SIMD技术简介
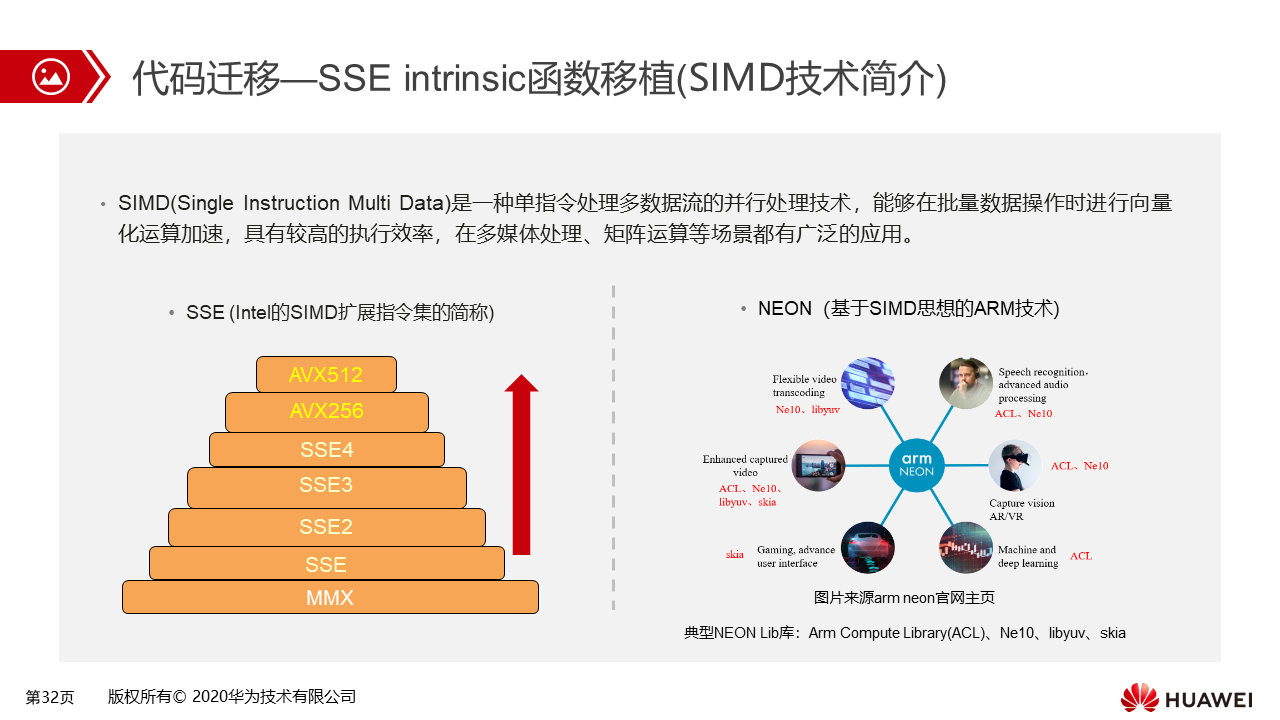
SIMD(Single Instruction Multi Data)是一种单指令处理多数据流的并行处理技术,能够在批量数据操作时进行向量化运算加速,具有较高的执行效率,在多媒体处理、矩阵运算等场景都有广泛的应用。SIMD功能的实现强烈依赖于SIMD寄存器,在一个多位的寄存器中存储多个同一数据类型的数据进行操作,完成向量操作加速。在x86和鲲鹏处理器下对该技术都进行了扩展,并有很好的支持。
x86下的SSE是Intel的SIMD扩展指令集的简称,由MMX发展而来,后续进一步发展了SSE2、SSE3、SSE4、AVX256、AVX512指令集(MMX、SSE/SSEX、AVX256、AVX512分别依赖64、128、256、512位寄存器)。
在鲲鹏处理器下,我们也支持了NEON技术,NEON也是一种基于SIMD思想的Arm技术,使用128位的NEON寄存器进行单指令多数据的向量化操作,具有较高的执行效率。当前基于NEON特性的lib加速库很多,他们在矩阵运算、机器学习、计算机视觉、图像处理等相关领域有着广泛应用,典型lib库有:Arm Compute Library(ACL)、Ne10、libyuv、skia 。包括我们熟悉的opencv视觉库也应用了大量的NEON特性加速基础图像处理函数性能。
为了便于开发者使用SSE/NEON功能,编译器对底层的SIMD类指令进行了进一步抽象集成,提供了相关头文件、API接口来支持C/C++高级语言调用,这类函数我们称为SSE/NEON Intrinsic函数。
SSE/NEON Intrinsic函数是一些列C函数调用(编译器builtin函数的进一步封装),编译器可将其替换为适当的SSE/NEON指令或SSE/NEON指令序列。SSE/Neon Intrinsic函数几乎提供与编写SSE/NEON汇编指令相同的功能,但是将寄存器分配等工作留给编译器,以便开发人员可以专注于算法开发。
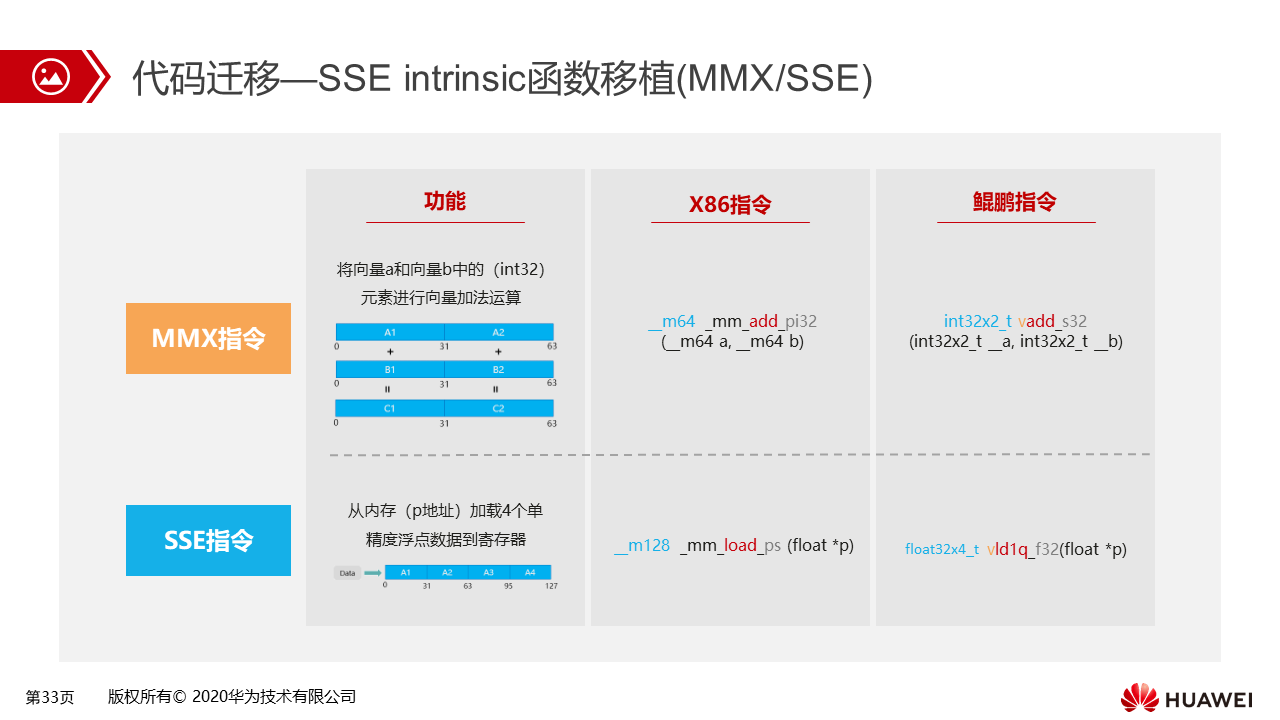
MMX(64位寄存器)、SSE(128位)类intrinsic函数的移植
MMX类移植的主要点是add字样,这是该函数的核心SSE指令含义。add就是在一条指令作用下降寄存器里的两个数一次性相加,存在C寄存器中。同样在鲲鹏处理器下,NEON指令集也有相应的功能函数进行等价替换,基于鲲鹏下函数的语法规则传参数就完成了替换。
SSE指令同样道理进行替换,这里示例是一次性加载4个float数据到128位的寄存器中,x86下的核心关键字是load,在鲲鹏处理器下也存在对应的NEON Intrinsic函数,其关键字是vld1q,逐一通道进行数据连续加载。
通过以上过程,我们发现这其实是C函数层面的替换实现,只是两类接口的一个对应实现和替换,在熟悉SSE NEON Intrinsic函数的使用规则后,可以做到一个较快替换。
案例介绍:
- x86下SSE Intrinsic函数形式,这里列举了两类SSE Intrinsic函数,分别为64位的MMX 和128位寄存器的SSE指令。函数的返回类型是__m64/128,其分别表示64/128位对应的数据类型。add和load分别为加法指令和加载数据指令。p表示package操作,s/i32表示操作的数元素分别为单精度浮点和int32数据类型。 对于64位的MXX寄存器,其一个寄存器可存储2个32位的int数据,可一次性实现两个int32数据相加。同理,对于128位的SSE类型寄存器,其可以存储4个float数据,可一次实现4个浮点数据的加载。
- 同样在鲲鹏处理器下,NEON指令集也有相应的功能函数进行等价替换。
如int32x2_t vadd_s32 ()函数,int32x2_t 表示64位的寄存器,可存储2个int32数据 ,V是向量操作的标记符,add为加法指令。s32位有符号整除int32数据类型 。
float32x4_t vld1q_f32()函数,float32x4_t表示128位寄存器,可存储4个float数据,V是向量操作的标记符,ld1q为数据加载指令(代表逐一通道加载)。 f32表示float32数据类型
AVX指令
AVX指令与MXX/SSE指令迁移类似,关键差别在于需要使用128位寄存器下的NEON指令函数拼接实现256位寄存器的SIMD指令功能。
示例中是16个单精度浮点进行相加,鲲鹏下可由NEON指令两次add求和实现。

SSE Intrinsic函数移植方法
SSE Intrinsic函数移植方法主要有两种,基于avx2neon.h、SSE2NEON.h开源文件移植以及手动替换移植。
- 基于开源的替换头文件进行移植,主要基于有以下两个开源项目:鲲鹏AvxToNeon开源工程(编译选项:-march=armv8-a+fp+simd+crc)、开源的SSE2NEON工程。这两个开源工程分别针对Avx指令类和SSE指令类函数的替换。
- 手动替换移植。结合SSE、NEO intrinsic的指导网站信息,手动完成对相应函数的实现。这里注意下,在手动替换是要记得添加arm_neon.h函数,这里包含了NEON Intrinsic函数的实现接口。
基于开源的替换头文件进行移植
- 在GitHub上下载开源的AvxToNeon工程和SSE2NEON.h文件,将“avx512intrin.h\avxintrin.h\emmintrin.h\typedefs.h\SSE2NEON.h”置于需移植文件的同级目录。
- 删除原文件中SSE相关头文件语句。(如:mmintrin.h、xmmintrin.h、pmmintrin.h、avx2intrin.h等)
- 增加现有avx2neon.h、SSE2NEON.h头文件语句(编译选项 -march=armv8-a+fp+simd+crc)。
手动替换移植
- 在SSE的Intrinsics Guide网站查看SSE Intrinsic函数的功能描述及伪代码实现。
- 选择Neon Intrinsic中合适的数据结构对SSE函数相关数据类型进行替换。
- 在NEON Intrinsic网站中,查找与SSE Intrisic函数类似功能的Neon函数和用法。
- 在需移植文件中添加头文件:#include <arm_neon.h>。
- 参考SSE Intrinsic伪代码,灵活的使用Neon Intrinsic函数实现SSE相关函数功能。
