开源MySQL参考架构
方案架构选择需要根据业务具体场景选用最适合的架构,鲲鹏BoostKit数据库场景白皮书只提供典型架构参考,开源数据库部分客户根据具体业务选择所需的方案架构,商业数据库部分由数据库厂家提供技术方案和支持。
组件场景
开源MySQL是典型的
OLTP的基本特点:
- 数据在系统中产生。
- 基于交易的处理系统(Transaction-Based)。
- 每次交易牵涉的数据量很小。
- 对响应时间要求非常高。
- 用户数量非常庞大,主要是操作人员。
- 数据库的各种操作主要基于索引进行。
架构原理
MySQL架构如图1所示。
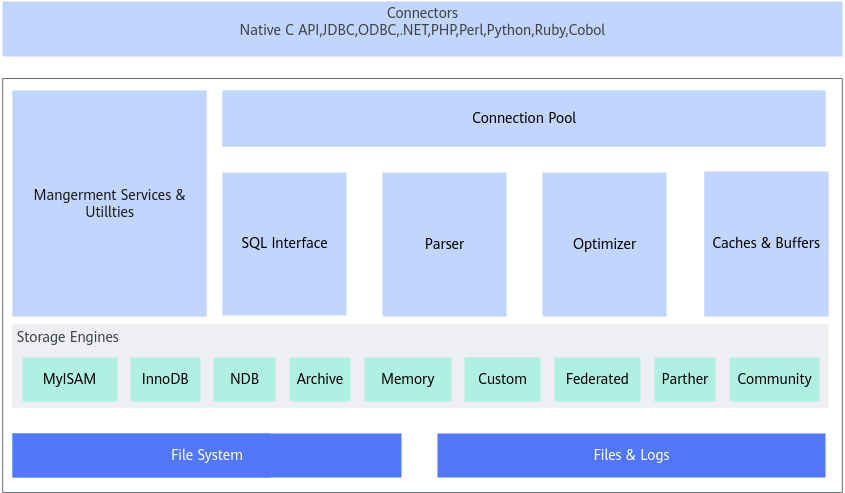
MySQL系统架构图各个组件说明如表1所示。
|
组件 |
说明 |
|---|---|
|
Connectors |
与其他编程语言中的SQL语句进行交互,如PHP、Java等。 |
|
Management Services & Utilities |
系统管理和控制工具。 |
|
Connection Pool(连接池) |
管理缓冲用户连接,线程处理等需要缓存的需求。 |
|
SQL Interface(SQL接口) |
接受用户的SQL命令,并且返回用户需要查询的结果。例如select from就是调用SQL Interface。 |
|
Parser(解析器) |
SQL命令传递到解析器的时候会被解析器验证和解析。 主要功能:
|
|
Optimizer( |
SQL语句在查询之前会使用查询优化器对查询进行优化(产生多种执行计划,最终数据库会选择最优化的方案去执行,尽快返回结果),它使用的是“选取-投影-连接”策略进行查询。 |
|
Caches和Buffers(查询缓存) |
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。 这个缓存机制是由一系列小缓存组成的。例如表缓存、记录缓存、key缓存、权限缓存等。 |
|
Storage Engines(存储引擎) |
存储引擎是MySQL中具体的与文件打交道的子系统,也是MySQL最具有特色的一个地方。 MySQL的存储引擎是插件式的。它根据MySQL AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎)。 |
组件典型架构
MySQL参考架构如图2所示。
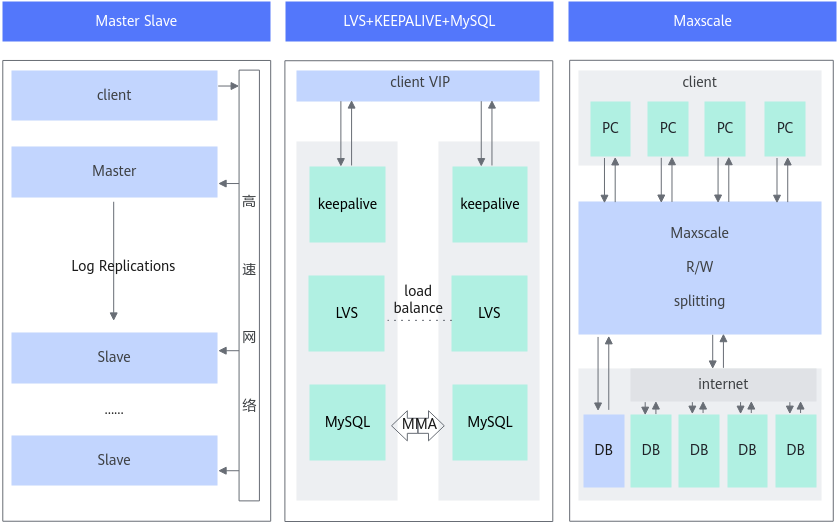
包括以下几种常用参考架构:
- Source、Replica主备复制方案
- LVS+KEEPALIVE+MySQL高可用方案
- Maxscale读写分离,负载均衡方案
在部署多个实例或使用分布式架构时,建议每台服务器上绑定多个实例到CPU,这样能更有效地利用资源,提升整体性能。