部署OSD节点
划分OSD分区

以下操作在3个ceph节点均执行一遍,此处以/dev/nvme0n1和/dev/nvme1n1为例说明,如果有多块NVMe SSD或SATA/SAS接口SSD,只需将脚本中的/dev/nvme0n1和/dev/nvme1n1盘符替换为对应盘符即可。对于非推荐配置,若NVMe盘划分的DB分区和WAL分区空间不足,将会放到HDD中,影响性能。
Ceph 14.2.8采用了BlueStore作为后端存储引擎,没有了Jewel版本的Journal盘分区的划分,而是变成DB分区(元数据分区)和WAL分区。这两个分区分别存储BlueStore后端产生的元数据和日志文件。在集群部署时,每个Ceph节点配置2块2.9TB(或2块7TB)的NVMe盘。一般WAL分区大于10GB就足够使用,Ceph官方文档建议每个DB分区不小于每个数据盘容量的4%,具体可根据NVMe盘容量灵活设置。基于当前NVMe盘,采用如下推荐配置,NVMe盘划分为12个10GB分区、12个25GB分区,分别对应WAL分区、DB分区,剩余NVMe盘额外划分为两个分区,后续Global Cache服务端部署中BDM初始化时使用。
数据盘大小 |
DB分区 |
WAL分区 |
BDM分区 |
|---|---|---|---|
2*2.9TB |
12*25GB |
12*10GB |
2*2.7TB |
2*7TB |
12*25GB |
12*10GB |
2*6.8TB |
- 创建一个partition.sh脚本。
1vi partition.sh - 添加如下内容:
#!/bin/bash parted -s /dev/nvme0n1 mklabel gpt parted -s /dev/nvme1n1 mklabel gpt start=4 # 交叉划分6个10G分区和6个25G分区 for i in {1..6} do end=`expr $start + 10240` parted /dev/nvme0n1 mkpart primary ${start}MiB ${end}MiB parted /dev/nvme1n1 mkpart primary ${start}MiB ${end}MiB start=$end end=`expr $start + 25600` parted /dev/nvme0n1 mkpart primary ${start}MiB ${end}MiB parted /dev/nvme1n1 mkpart primary ${start}MiB ${end}MiB start=$end done parted /dev/nvme0n1 mkpart primary ${end}MiB 100% parted /dev/nvme1n1 mkpart primary ${end}MiB 100%
此脚本内容只适用于当前硬件配置,其它硬件配置可参考此脚本。
- 创建完脚本后执行脚本。
1bash partition.sh
部署OSD节点
以下脚本的“/dev/sda-/dev/sdl”12块硬盘均为数据盘,OS安装在“/dev/sdm”上。实际情况中可能会遇到OS硬盘位于数据盘中间的情况,例如系统盘安装到了“/dev/sde”,则不能直接使用以下脚本直接运行,否则部署到“/dev/sde”时会报错。此时需要重新调整脚本,避免脚本中包含数据盘以外的如OS盘、做DB/WAL分区的SSD盘等。
- 确认各个节点各硬盘的sd*。
1lsblk
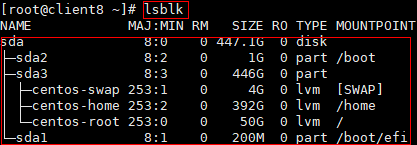 如图代表/dev/sda是系统盘。
如图代表/dev/sda是系统盘。
有一些硬盘可能是以前Ceph集群里的数据盘或者曾经安装过操作系统,那么这些硬盘上很可能有未清理的分区,lsblk命令可以看到各个硬盘下是否有分区。假如/dev/sdb硬盘下发现有分区信息,可用如下命令清除:
1ceph-volume lvm zap /dev/sdb --destroy
必须先确定哪些盘做为数据盘使用,当数据盘有未清理的分区时再执行清除命令。
- 在ceph1上创建脚本create_osd.sh,将每台服务器上的12块硬盘部署OSD。
1 2
cd /etc/ceph/ vi /etc/ceph/create_osd.sh
添加以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
#!/bin/bash for node in ceph1 ceph2 ceph3 do j=1 k=2 for i in {a..f} do ceph-deploy osd create ${node} --data /dev/sd${i} --block-wal /dev/nvme0n1p${j} --block-db /dev/nvme0n1p${k} ((j=${j}+2)) ((k=${k}+2)) sleep 3 done j=1 k=2 for i in {g..l} do ceph-deploy osd create ${node} --data /dev/sd${i} --block-wal /dev/nvme1n1p${j} --block-db /dev/nvme1n1p${k} ((j=${j}+2)) ((k=${k}+2)) sleep 3 done done
- 此脚本内容只适用于当前硬件配置,其他硬件配置可参考此脚本。
- ceph-deploy osd create命令中:
- ${node}是节点的hostname。
- --data选项后面是作为数据盘的设备。
- --block-db选项后面是DB分区。
- --block-wal选项后面是WAL分区。
DB和WAL通常部署在NVMe SSD上以提高写入性能,如果没有配置NVMe SSD或者直接使用NVMe SSD作为数据盘,则不需要--block-db和--block-wal,只需要--data指定数据盘即可。
- 在ceph1上运行脚本。
1bash create_osd.sh - 创建成功后,查看是否正常,即36个OSD是否都为up。
1ceph -s