Hyper MPI中并非每一个算法都支持所有的场景,以下几种场景属于部分算法支持。
场景一:节点进程不均衡(即PPN不均衡)
使用mpirun命令提交任务不指定PPN或者使用rankfile等情况下,会出现节点进程不均衡的场景,当指定Hyper MPI中Allreduce算法11、13、14,Allgatherv算法6,Scatterv算法3,Barrier算法10,Alltoallv算法2时,会自动回退至支持的算法。
场景二:Socket进程不均衡(即PPS不均衡)
使用mpirun命令提交任务不指定PPS或者使用rankfile等情况下,会出现Socket进程不均衡的场景,当指定Hyper MPI中Allreduce算法13、14时,会自动回退至支持的算法。
场景三:非对易操作
MPI标准支持用户在Allreduce内进行自定义数学操作,即不局限于求和(MPI_SUM)、乘积(MPI_PROC)等MPI内置的数学操作;用户在自定义数学操作时会出现操作本身不对易的情况,如矩阵乘法。Allreduce算法1支持此类操作。
当用户指定算法不是算法1时,Hyper MPI会根据数据包大小回退成算法1(中小包)。
场景四:指定--bind-to none或者--bind-to board
当MPI指定--bind-to为none或者board时,Allreduce算法3、6、8、13、14和Barrier算法3、5、7不支持此场景,会自动回退至支持的算法。
场景五:发送的数量count小于所有节点进程数np或所有节点进程数减一
当发送的数量count小于所有节点进程数np时,Allreduce算法4、12、13、14和Bcast算法8、11不支持此场景,会自动回退至支持的算法。
当发送的数量count小于所有节点进程数减一(np-1)时,Bcast算法14和Bcast卸载算法3、4不支持此场景,会自动回退至支持的算法。
场景六:发送的数量count对ppn取余不等于0
当发送的数量count对ppn取余不等于0时,Allreduce算法13不支持此场景,会自动回退至支持的算法。
场景七:PPS为1
当PPS=1时,Allreduce算法14不支持此场景,会自动回退至支持的算法。
场景八:PPN为1
当PPN=1时,Allreduce算法11、13、14,Allgatherv算法6,Scatterv算法3,Barrier算法10,Alltoallv算法2不支持此场景,会自动回退至支持的算法。
场景九:np不为二的N次方
当np不为二的N次方时,Allreduce算法11,Barrier算法10不支持此场景,会自动回退至支持的算法。
场景十:np为奇数
当np为奇数时,Hyper MPI中Allgatherv算法1不支持此场景,会自动回退至支持的算法。
场景十一:指定--rank-by node或者--rank-by board
当MPI指定--rank-by node或者--rank-by board时,Alltoallv算法2和Scatterv算法3不支持此场景,将自动回退至支持的算法。
场景十二:节点数为1
当节点数为1时,Hyper MPI中Alltoallv算法2、Allgatherv算法6和Scatterv算法3不支持此场景,将自动回退至支持的算法。
场景十三:sendbuf为MPI_IN_PLACE
当sendbuf为MPI_IN_PLACE时,Hyper MPI中Alltoallv所有算法和Scatterv算法3不支持此场景,回退到Open MPI。
场景十四:Alltoallv集合操作send或recv total size超过2^32 - 1
此场景下,Hyper MPI中Alltoallv算法2(node-aware plummer)由于是运行时数据,无法在回退时给出判断,会在运行时报错,并给出提示“Alltoallv node-aware plummer don't support data
size >= 2^32 bytes”。
场景十五:Alltoallv集合操作节点内所有进程sendcounts总和超过2^31
此场景下,Hyper MPI中Alltoallv算法2(node-aware plummer)由于是运行时数据,无法在回退时给出判断,会在运行时报错,并给出提示“Alltoallv node-aware plummer gatherv phase don't support displs >= 2^31 bytes”,sendcounts总和计算公式如下:
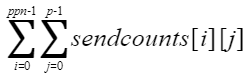
其中,p为总进程数;ppn为每节点进程数;sendcounts[i]为节点内第i个进程的sendcounts数组。
场景十六:Alltoallv集合操作各进程sendcounts和recvcounts大小不一致
此场景下,若命令参数中不指定Alltoallv的具体算法,可能会出现不同进程回退到不同算法的情况,导致程序卡住无法正常运行。在确保各进程sendcounts和recvcounts大小一致的情况下,可以不指定Alltoallv的具体算法,默认选择性能最优算法。
场景十七:进程数小于3
当进程数小于3时,Bcast卸载算法1不支持此场景,将自动回退至支持的算法。
场景十八:进程数小于4
当进程数小于4时,Bcast卸载算法2不支持此场景,将自动回退至支持的算法。