使用毕昇编译器进行内存布局优化
发表于 2023/09/19
0
尊敬的鲲鹏开发者您好,毕昇编译器是鲲鹏架构下使能极致性能的编译器,访存瓶颈是应用常见的性能瓶颈。本文旨在帮助开发者更好地理解程序的内存行为,定位程序中由于内存布局导致的性能瓶颈,通过使用毕昇编译器提高程序的性能,为后续基于鲲鹏架构下的系统与硬件设计提供指导。您可以阅读本篇文档进行毕昇编译器内存布局优化的快速入门。
本篇文档主要介绍了以下知识:
(1)编译器内存布局优化原理
(2)如何使用毕昇编译器进行内存布局优化
基础技能:
(1)具备基础的C/C++语言编程能力
(2)了解常用的Linux操作命令编译器内存布局优化原理
结构体、数组的内存布局由编译器控制,编译器可以结合结构体声明、访问特征以及微架构特征来灵活设计新的数据布局来改善数据局部性,从而提升缓存利用率。
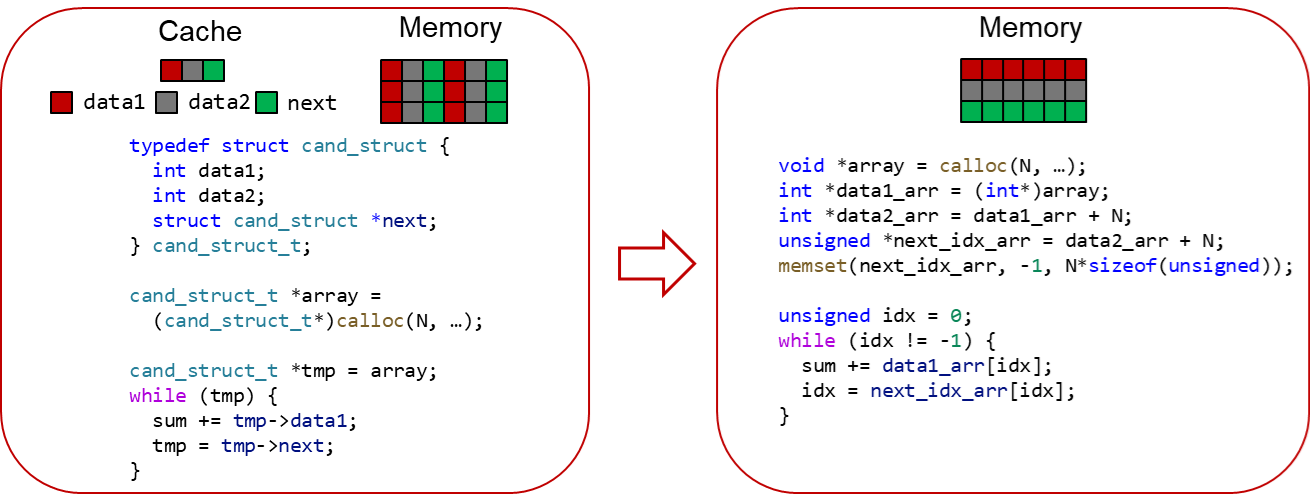
以图中代码为例,结构体的字段data1, data2, next在一个结构体中顺序排列,对于结构体数组array,其内存布局为data1, data2, next, data1, data2, next, … 等字段交替排列。而当array被访问时,仅仅访问每个结构体的data1字段,此时每个对data1的访问都不是连续的,中间间隔了data2, next字段。这样的访存模式往往内存局部性较差,会引发较高的cache miss。毕昇编译器的结构体内存布局优化可以将结构体数组重新布局为数组的结构体,从而保证每个data1字段的访问是内存连续的。
使用毕昇编译器进行内存布局优化
本节将基于上述编译器内存布局优化原理动手实操如何使用毕昇编译器进行内存布局优化。
由于创建鲲鹏工程编译运行的过程需要在鲲鹏平台上完成,为了方便开发者在鲲鹏环境上进行开发,我们提供了鲲鹏远程实验室资源供大家免费申请。
为了兼顾所有鲲鹏开发者的开发体验,我们在鲲鹏远程实验室中提供了云开发环境(开发态模式)和远程服务器(黑框模式)。接下来的体验过程我们会在云开发环境上进行,开发者在申请云开发环境后可以直接通过在线IDE的方式打开页面进行操作。降低开发者在鲲鹏上的开发门槛。
因此,开发者需要先申请鲲鹏远程实验室资源:
步骤 1 访问鲲鹏社区的远程实验室页面。
首先我们访问鲲鹏社区的远程实验室页面https://www.hikunpeng.com/zh/developer/cloud-lab,申请云开发环境:
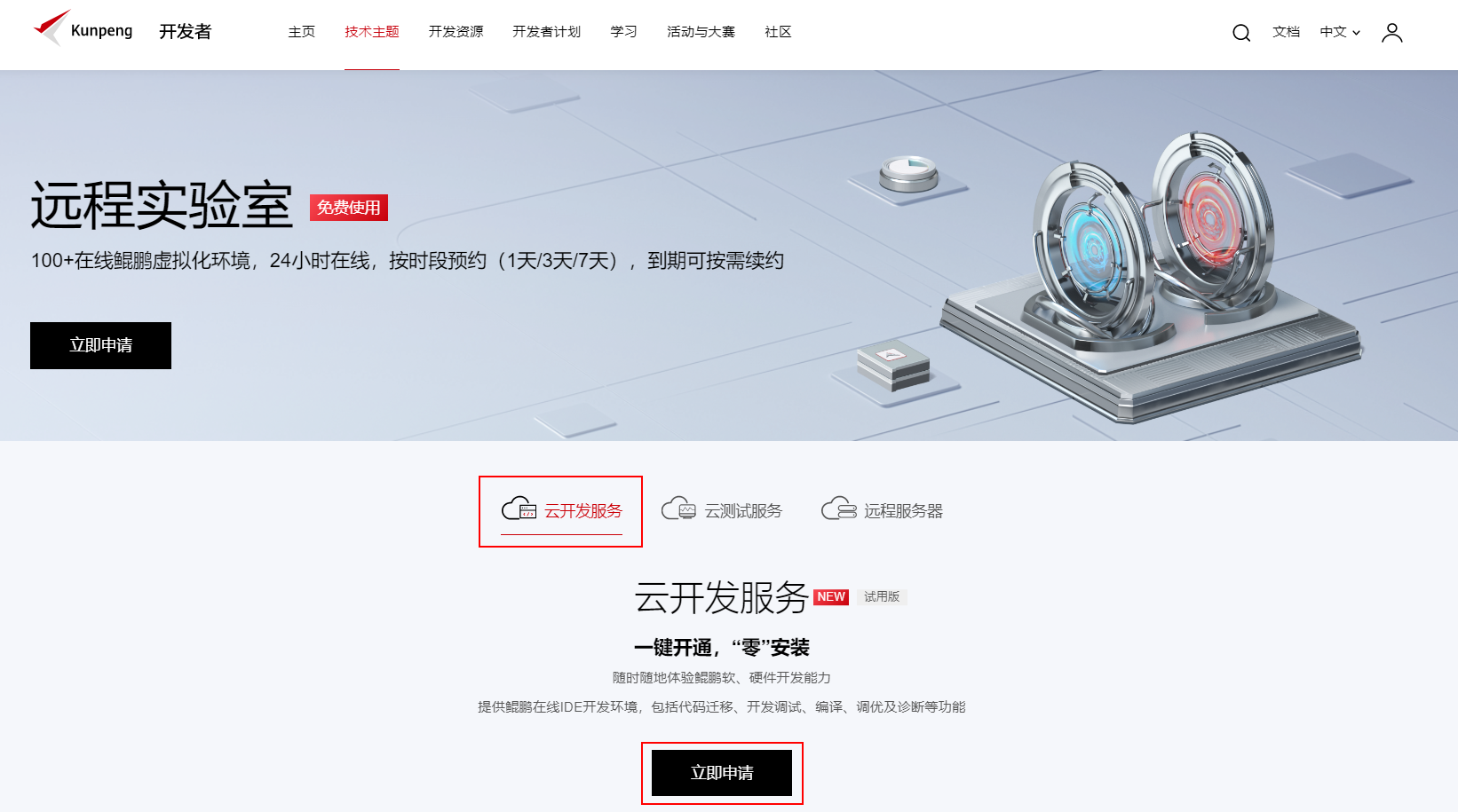
之后我们输入自己的邮箱地址,选择openEuler 20.03 LTS-SP1系统,申请成功后我们点击“打开在线IDE”按钮,进入云开发环境中,云开发环境给大家提供了在线Vscode页面,方便我们直接在鲲鹏上进行开发。
步骤 2 创建test.c文件,并将如下代码拷贝至test.c文件中。
#include <stdlib.h>#include <math.h>typedef struct {int a;double b;char c;float d;short e;int f;} str_t1;typedef struct{str_t1 tmp;str_t1 *st;} str_t2;str_t2 glob_struct;#ifdef STACK_SIZE#if STACK_SIZE > 16000#define N 1000#else#define N (STACK_SIZE/16)#endif#else#define N 1000#endifint num;int main (){int i, r;r = rand();num = 300000000;str_t1 * p1 = (str_t1*)calloc (num , sizeof (str_t1));glob_struct.st = p1;if (glob_struct.st == NULL)return 0;for (i = 0; i < num; i++)glob_struct.st[i].a = 1;return 0;}
在上述代码中,结构体str_t1有a,b,c,d,e,f六个成员,每个结构体的内存空间按照a-f六个成员的顺序排列,经过calloc调用后p1指向一个较长的结构体数组。在后面的for循环中频繁使用结构体成员变量a,而没有使用其他的元素。因此每次针对a的访问都跨过了其他变量b-f,导致访存的本地性较差,产生较高的cache miss。为了解决这个问题,编译器可以将p1的内存重新排布,从结构体数组变为数组的结构体。这样每次针对a的访问就变成了一个连续的访问。
步骤 3 编译运行。
clang test.c -O3 -flto -fuse-ld=lld -o test.struct-peel.exe && time ./test.struct-peel.exereal 0.81s【注意:此结果不唯一】
clang test.c -O3 -flto -fuse-ld=lld -Wl,-mllvm,-enable-struct-peel=false -o test.no-struct-peel.exe && time ./test.no-struct-peel.exereal 6.5s【注意:此结果不唯一】
步骤 4 将生成的二进制文件反汇编。
objdump -d test.struct-peel.exe &> test.struct-peel.dumpobjdump -d test.no-struct-peel.exe &> test.no-struct-peel.dump步骤 5 统计test.struct-peel.dump和 test.no-struct-peel.dump中,对calloc跳转的个数。
grep "bl.*calloc" test.struct-peel.dump | wc -l6grep "bl.*calloc" test.no-struct-peel.dump | wc -l1从上述输出可以看到,开启结构体内存布局优化后,生成的汇编中对calloc的调用个数从1个变为了6个。即针对每个结构体的成员变量,通过calloc申请一段数组内存。
恭喜
到这里整个实验流程就已经结束了,通过上面的实验我们可以了解编译器内存布局优化的原理以及毕昇编译器内存布局优化的过程。
除了上述学习内容,我们还提供了很多辅助学习资源(课程/实验/文档/文章),希望能帮助到您更好的使用毕昇编译器:
基于毕昇编译器实现鲲鹏架构下编译性能提升25%(课程):
https://www.hikunpeng.com/learn/courses-list/detail/381811335166300160
沙箱实验:
https://www.hikunpeng.com/learn/experiments/detail/T221127001
毕昇编译器用户指南(文档):
毕昇编译器Autotuner特性指南(文档):
本页内容