


如何使用OmniRuntime算子下推提升大数据引擎计算性能
发表于 2023/07/29
0
OmniData本质是实现近数据计算,即通过在数据获取阶段做存算协同,把不需要的数据量过滤掉,使得传递给下面做计算的那部分数据尽可能保留有效数据,在计算侧CPU能够计算的东西比较少之后,一方面降低降网络开销,更重要的一点是把CPU的负担降下来。在介绍如何部署和使用OmniData之前,我们先通过一些基础知识和示例帮助您更好的理解OmniData如何进行算子下推。
理解OmniData
要做算子下推的话,主要需要判断三个依据是:
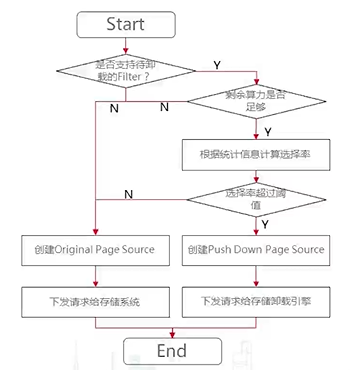
(1)查询语句中是否支持待卸载的Filter。
(2)存储节点的CPU是否有足够的计算资源。
(3)选择率是否超过阈值,即数据读取的行数与数据处理之后的行数的比值,比值越小,说明选择率越低,带来过滤效果越好。
例如此处以Filter算子为例,如果要将Filter算子下推到存储节点,具体的判断过程如下图所示。
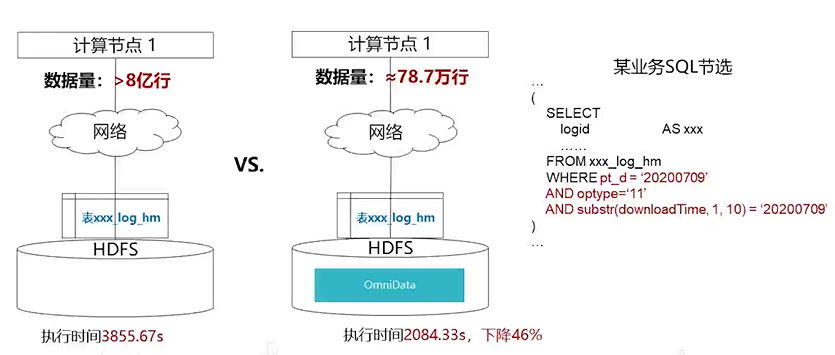
下面我们以一个具体实例来描述使用了OmniData之后的效果。
从某个业务SQL中节选了一段命令,命令中红色字体部分为前面提到的需要过滤的部分,也就是我们所说的算子部分,从图中我们可以看到有3个过滤条件,没有用OmniData之前,可以过滤掉optype和substr两块数据,但剩下的数据部分没有做过滤,通过网络直接从存储节点传到了计算节点,数据量大约有8亿行。计算节点首先要过滤无效数据,然后再进行计算,这种情况下对于计算算力的消耗非常大,计算节点做了很多无效计算,导致执行时间变长。
使用了OmniData之后,会在存储节点先过滤掉无效数据,然后将筛选后的有效传到计算节点,数据量只剩78万行,大幅减少了网络流程,计算执行时间也降低了46%,可以看到OmniData带来的SQL计算性能效果提升还是很明显的。
对于Spark引擎来说,一个算子是否要被下推?我们从两方面讨论:
(1)是否需要下推
一般来说,下推可以获得更好的速度与性能,但这在大数据量的OLAP场景中不是绝对的。假设你的Spark资源非常充裕,而作为OmniData数据源的压力较大,如果还进行下推特别是消耗资源较大的聚合下推,反而会使得整体执行速度降低,转而将压力放到资源充分的Spark则是更合理的选择。因此对于一些资源消耗大的算子,我们应该由实际情况决定是否下推。OmniData提供了一些可配置的参数到Spark的配置文件(“$SPARK_HOME/conf/spark-defaults.conf”)中:
参数 | 推荐值 | 含义 |
|---|---|---|
spark.sql.ndp.enabled |
TRUE |
是否开启算子下推。 |
spark.sql.ndp.filter.selectivity.enable |
TRUE |
是否开启filter选择率来判断是否下推。 |
(2)能否被下推
算子不总是能下推,可能某些表达式,类型就会无法下推。这里的限制来源于两个方面的并集:Spark本身不支持、OmniData不支持。对于此OmniData会自动基于Spark与OmniData的能力决定是否下推,无需开发者选择。
OmniData下推数据类型限制如下:
1)数值类型进行计算时如果发生越界,OmniData会抛出数值越界异常。
2) 字符串类型比较时,常量必须被英文单引号包含。例如:select * from table where char = '123'。
3) 不支持decimal(38,38)数据类型。
4)不支持timestamp数据类型,走原生计算流程。
5)不支持对事务表的算子下推,走原生计算流程。
6) 不支持对分桶表的算子下推,走原生计算流程。
7) 必须保证数据表的analyze为最新,否则下推选择率判断不准确。
OmniData部署方案
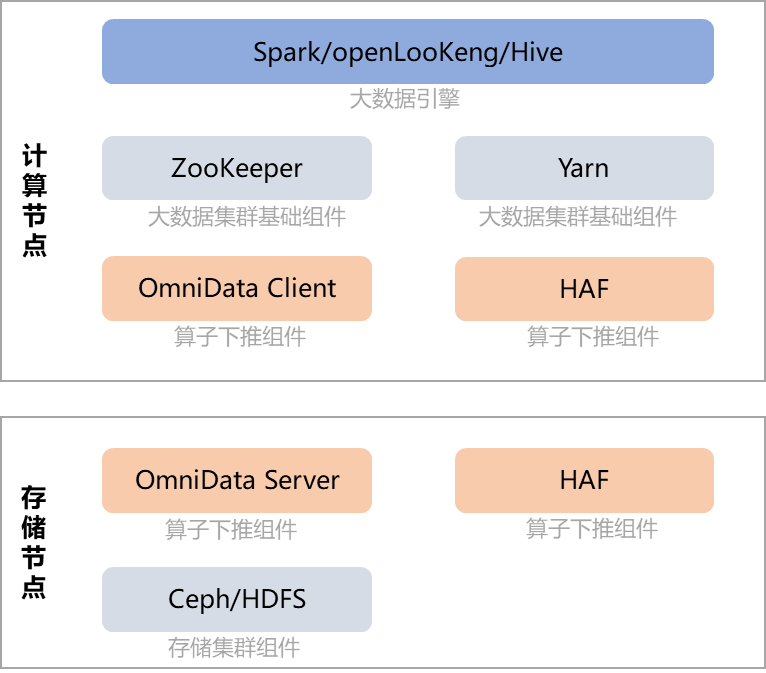
OmniData部署方案如图3-1所示,您可根据需要提前在计算节点安装所需的大数据引擎(Spark/openLooKeng/Hive),在存储节点安装存储集群(HDFS/Ceph)。您可以采用单机部署模式,即一台服务器同时充当计算节点和存储节点,也可以采用集群部署模式,即使用存算分离组网,部署1台管理节点+3台计算节点组成大数据计算集群,部署3台存储节点组成存储集群。其中OmniData相关的组件在整个部署方案中的作用如下:
(1)OmniData Client属于开源的部分,为不同的大数据引擎(Spark/openLooKeng/Hive)提供相应的插件。通过HAF提供的注解和编译插件,在需要下推的函数上添加注解,HAF会自动把任务下推到卸载节点的OmniData Server中,让开发者感觉好像在本地执行一样。
(2)HAF包含两部分,一部分是HAF Host Runtime lib库,部署在计算节点,对外提供任务卸载的能力,把任务下推到HAF Target Runtime。另一部分是HAF Target Runtime lib库,部署在存储节点,对外提供任务执行的能力,用来执行OmniData Server的作业。
(3)OmniData Server提供算子下推(算子卸载)的执行能力,接收HAF下推下来的任务。
图3-1 OmniData部署方案
部署节点 | 大数据引擎 | 大数据集群基础组件 | 算子下推组件 | 存储集群组件 |
|---|---|---|---|---|
计算节点 |
Spark/openLooKeng/Hive |
ZooKeeper、Yarn |
OmniData Client、HAF |
- |
存储节点 |
- |
- |
OmniData Server、HAF |
Ceph/HDFS |
基于前面介绍的OmniData部署方案,相信您对OmniData在整个大数据集群中所处的位置和所起的作用已经有一定的了解了,接下来我们将简单介绍如何在鲲鹏平台环境上部署OmniData相关组件,开发者可以使用自备的鲲鹏平台环境进行学习和实操。
OmniData相关组件的部署环境要求如表3-1所示:
表3-1 部署OmniData相关组件的软硬件环境要求
项目 | 类别 | 说明 | 下载地址 |
|---|---|---|---|
服务器硬件(管理/计算/存储节点) |
服务器名称 |
TaiShan服务器 |
-- |
处理器 |
鲲鹏920 5220处理器 |
-- |
|
内存大小 |
384GB (12 * 32GB) |
-- |
|
内存频率 |
2666MHz |
-- |
|
网卡 |
(1)Ceph环境:业务网络25GE,管理网络GE |
-- |
|
硬盘 |
(1)系统盘:1 * RAID
0(1 * 1.2T SAS HDD) |
-- |
|
RAID卡 |
LSI SAS3508 |
-- |
|
节点操作系统 |
OS |
(1)CentOS
7.6 |
请自行准备操作系统镜像并安装到服务器节点上。 |
管理节点软件要求 |
编译环境 |
BiSheng JDK 1.8(优选BiSheng JDK 1.8.0_342) |
openEuler 22.03 LTS与BiSheng JDK
1.8.0_262不兼容,需更换为BiSheng JDK 1.8.0_342。 |
大数据基础组件 |
Hadoop 3.2.0 |
请自行获取开源软件源码并参考鲲鹏社区的文档进行部署。 |
|
大数据引擎 |
Spark 3.0.0或Spark 3.1.1/openLooKeng 1.6.1/Hive 3.1.0 |
请自行获取大数据引擎软件包并参考鲲鹏社区的文档进行部署。 |
|
计算节点软件要求 |
编译环境 |
BiSheng JDK 1.8(优选BiSheng JDK 1.8.0_342)、OpenSSL 1.1.1及以上、Python 3.9.2及以上 |
openEuler 22.03 LTS与BiSheng JDK
1.8.0_262不兼容,需更换为BiSheng JDK 1.8.0_342。 |
大数据基础组件 |
Hadoop 3.2.0、ZooKeeper 3.6.2 |
请自行获取开源软件源码并参考鲲鹏社区的文档进行部署。 |
|
OmniData组件 |
OmniData 1.4.0、HAF 1.3.0 |
||
存储节点软件要求 |
编译环境 |
BiSheng JDK 1.8(优选BiSheng JDK 1.8.0_342)、OpenSSL 1.1.1及以上、Python 3.9.2及以上 |
openEuler 22.03 LTS与BiSheng JDK
1.8.0_262不兼容,需更换为BiSheng JDK 1.8.0_342。 |
存储集群组件 |
Ceph 14.2.8,如果存储服务使用HDFS,则需要部署Hadoop 3.2.0,部署Hadoop时包含HDFS。 |
请自行获取开源软件源码并参考鲲鹏社区的文档进行部署。 |
|
OmniData组件 |
OmniData 1.4.0、HAF 1.3.0 |
基于上面OmniData相关组件的软硬件部署要求,请自行准备鲲鹏平台环境,并参考如下步骤进行OmniData相关组件的部署和配置。下面的操作步骤仅给出了OmniData部署时的主要流程和关键操作任务,关于部署过程中所需的软件包要求和详细的部署过程请参考《OmniRuntime OmniData特性指南》。
步骤 1:确认各个节点上已部署基础组件。
(1)管理节点上已部署大数据基础组件、大数据引擎和必要的编译软件。
(2)计算节点上已部署大数据基础组件和必要的编译软件。
(3)存储节点上已部署存储集群组件和必要的编译软件。
开源组件Zookeeper、Hdaoop、Spark、openLooKeng、Hive、Ceph不属于OmniData特性交付内容,因此这部分需要开发者提前确认部署情况。
步骤 2:安装HAF。
(1)创建安装目录,并将HAF安装包上传至安装目录下。
(2)在存储节点上安装HAF软件。
(3)在计算节点上安装HFA软件。
步骤 3:安装OmniData。
(1)将OmniData安装包上传至安装目录下。
(2)在存储节点安装OmniData软件。
(3)在存储节点生成OmniData配置文件。
步骤 4:配置OmniData。
(1)OmniData服务启动时需要读取HDFS/Ceph的配置文件,因此需要上传hdfs-site.xml和core-site.xml配置文件到存储节点OmniData的“etc”目录下面。
(2)当集群中HDFS和ZooKeeper为安全模式时,需要在存储节点添加Kerberos配置内容到“/home/omm/omnidata-install/omnidata/etc/config.properties”中。同时将相关配置文件(krb5.conf、hdfs.keytab、client_jass.conf等)拷贝到存储节点OmniData的“etc”目录下面。
步骤 5:运行OmniData。
(1)在存储节点运行OmniData服务。
(2)在存储节点查看OmniData服务状态。
----结束
Spark引擎应用OmniData
大数据查询引擎在金融、安平、运营商行业应用场景越来越多,是客户重要的感知场景,OmniData特性实现了大数据查询引擎在鲲鹏的优化,让开发者在不需要修改应用程序的情况下,提升开发者对鲲鹏的性能体验。OmniData性能优化组件以插件的形式部署到开发者的环境中,不影响引擎原有的功能,开发者可以根据实际需要选择性的开启或关闭优化特性,即可以通过配置Spark引擎配置文件来实现特性的开启或关闭。
步骤 1:配置Spark引擎,将OmniData参数配置到Spark的配置文件(“$SPARK_HOME/conf/spark-defaults.conf”)中。
(1)打开Spark配置文件。
vi $SPARK_HOME/conf/spark-defaults.conf(2)按“i”进入编辑模式,将下面参数配置添加到spark-defaults.conf中。
spark.sql.cbo.enabled true
spark.sql.cbo.planStats.enabled true
spark.sql.ndp.enabled true
spark.sql.ndp.filter.selectivity.enable true
spark.sql.ndp.filter.selectivity 0.5
spark.sql.ndp.alive.omnidata 3
spark.sql.ndp.table.size.threshold 10
spark.sql.ndp.zookeeper.address agent1:2181,agent2:2181,agent3:2181
spark.sql.ndp.zookeeper.path /sdi/status
spark.sql.ndp.zookeeper.timeout 15000
spark.driver.extraLibraryPath /home/omm/omnidata-install/haf-host/lib
spark.executor.extraLibraryPath /home/omm/omnidata-install/haf-host/lib
spark.executorEnv.HAF_CONFIG_PATH /home/omm/omnidata-install/haf-host/etc/以上的参数也可以通过set命令直接在spark-sql设置。
新增OmniData的参数信息如表3-2所示。
表3-2 OmniData的参数含义
参数 | 推荐值 | 含义 |
|---|---|---|
spark.sql.cbo.enabled |
TRUE |
是否开启cbo优化,设置为true时,启用cbo以估计执行计划来统计信息。 |
spark.sql.cbo.planStats.enabled |
TRUE |
设置为true时,逻辑计划将从目录中获取行和列的统计信息。 |
spark.sql.ndp.enabled |
TRUE |
是否开启OmniData。 |
spark.sql.ndp.filter.selectivity.enable |
TRUE |
是否开启filter选择率来判断是否下推。 |
spark.sql.ndp.filter.selectivity |
0.5 |
filter选择率小于该值才会下推(selectivity越小,表示需要过滤的数据量越小),缺省值为0.5,类型为double。 |
spark.sql.ndp.table.size.threshold |
10240 |
表大于该值才会下推,缺省值为10240,单位为字节。 |
spark.sql.ndp.alive.omnidata |
3 |
集群OmniData Server数量。 |
spark.sql.ndp.zookeeper.address |
agent1:2181,agent2:2181,agent3:2181 |
连接ZooKeeper地址。 |
spark.sql.ndp.zookeeper.path |
/sdi/status |
ZooKeeper存放下推资源信息的目录。 |
spark.sql.ndp.zookeeper.timeout |
15000 |
ZooKeeper超时时间,单位为ms。 |
spark.driver.extraLibraryPath |
/home/omm/omnidata-install/haf-host/lib |
Spark运行时Driver依赖的库文件路径。 |
spark.executor.extraLibraryPath |
/home/omm/omnidata-install/haf-host/lib |
Spark执行时Executor依赖的库文件路径。 |
spark.executorEnv.HAF_CONFIG_PATH |
/home/omm/omnidata-install/haf-host/etc/ |
使能HAF时的配置文件路径。 |
(3)按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
步骤 2:启动Spark SQL命令,执行sql6语句。.
在“/usr/local/spark/conf”目录下,定义日志文件log4j.properties。
(1)新建日志文件log4j.properties。
cd /usr/local/spark/conf
vi log4j.properties(2)按“i”进入编辑模式,在文件中添加以下内容。
log4j.rootCategory=INFO, FILE
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
log4j.logger.org.apache.spark.sql.execution=DEBUG
log4j.logger.org.apache.spark.repl.Main=INFO
log4j.appender.FILE=org.apache.log4j.FileAppender
log4j.appender.FILE.file=/usr/local/spark/logs/file.log
log4j.appender.FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.FILE.layout.ConversionPattern=%m%n(3)按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
(4)修改log4j.properties中的log4j.appender.FILE.file为自定义的目录和文件名。
(5)运行spark-sql命令时加日志项--driver-java-options -Dlog4j.configuration=file:/usr/local/spark/conf/log4j.properties,例如。
/usr/local/spark/bin/spark-sql --driver-class-path '/opt/boostkit/*' --jars '/opt/boostkit/*' --conf 'spark.executor.extraClassPath=./*' --name tpch_query6.sql --driver-memory 50G --driver-java-options -Dlog4j.configuration=file:/usr/local/spark/conf/log4j.properties --executor-memory 32G --num-executors 30 --executor-cores 18(6)执行sql6语句。
select
sum(l_extendedprice * l_discount) as revenue
from
tpch_flat_orc_1000.lineitem
where
l_shipdate >= '1993-01-01'
and l_shipdate < '1994-01-01'
and l_discount between 0.06 - 0.01 and 0.06 + 0.01
and l_quantity < 25;spark-sql命令参数信息如表3-3所示。
表3-3 OmniData的参数含义
参数 | 推荐值 | 含义 |
|---|---|---|
--driver-memory |
50G |
driver可用内存。 |
--executor-memory |
32G |
执行器可用内存。 |
--num-executors |
30 |
启动的执行器数量,缺省值为2。 |
--executor-cores |
18 |
每个执行器使用的CPU核数,缺省值为1。 |
--driver-class-path |
"/opt/boostkit/*" |
传递给驱动程序的额外JAR包的路径。 |
--jars |
"/opt/boostkit/*" |
驱动程序和执行器类路径中要包含的JAR包。 |
--conf |
"spark.executor.extraClassPath=./*" |
配置Spark参数。 |
--driver-java-options -Dlog4j.configuration |
file:/usr/local/spark/conf/log4j.properties |
log4j日志配置路径。 |
步骤 3:查看OmniData算子下推应用效果,并对比下推与不下推的差异。
(1)查看日志中OmniData算子下推信息,如下所示包含了下推的选择率以及算子信息,即OmniData成功运行。
vi /usr/local/spark/logs/file.log
Selectivity: 0.014160436451808448
Push down with [PushDownInfo(ListBuffer(FilterExeInfo((((((((isnotnull(l_shipdate#18) AND isnotnull(l_discount#14)) AND isnotnull(l_quantity#12)) AND (l_shipdate#18 >= 8401)) AND (l_shipdate#18 < 8766)) AND (l_discount#14 >= 0.05)) AND (l_discount#14 <= 0.07)) AND (l_quantity#12 < 25.0)),List(l_quantity#12, l_extendedprice#13, l_discount#14, l_shipdate#18))),ListBuffer(AggExeInfo(List(sum((l_extendedprice#13 * l_discount#14))),List(),List(sum#43))),None,Map(server1 -> server1, agent2 -> agent2, agent1 -> agent1))]
(2)查看使用OmniData算子下推后sql6语句运行耗时。
对比OmniData算子下推和原生Spark运行结果、运行时间,运行效率提升30%以上。
----结束