大数据OmniRuntime算子下推特性简介
发表于 2023/07/29
0
尊敬的鲲鹏开发者你好,随着互联网快速发展,数据规模出现了爆炸式增长,大数据开源生态也越来越丰富,但多样化的计算引擎和开源组件也同时带来了全生命周期数据处理性能提升难的问题。鲲鹏BoostKit正对大数据现状,推出大数据加速底座OmniRuntime,统一支撑不同引擎,减少重复优化。OmniRuntime包括算子下推(OmniData)、Shuffle加速(OmniShuffle)、算子加速(OmniOperator)、物化视图(OmniMV)等多个子特性,通过覆盖数据获取、交换、计算、缓存等全周期的性能优化,以插件化形式,对接不同的计算引擎,可实现大数据分析场景性能提升超过30%。
您可以通过本文章学习掌握在鲲鹏环境如何部署大数据OmniRuntime算子下推特性,以及如何在Spark引擎上应用算子下推的步骤。
本节主要介绍了以下知识:
(1)大数据OmniRuntime算子下推特性简介。
(2) 如何使用OmniRuntime算子下推提升大数据引擎计算性能。
随着互联网和智能化的相关发展,需要处理的数据量越来越大,呈现爆炸式的增长。而与此同时,CPU算力却远远滞后于数据量的增长。在这种情况下,如何更好的发挥CPU算力,应对数据不断增长的需求,就成为一个急需解决的问题。例如在大数据方面,就有大量的数据需要处理。
(1)在数据获取阶段,没有很好的方法过滤掉不必要数据。
(2)在数据处理阶段,因为大数据的数据层和控制层在逻辑层面紧密耦合的,优化难度高,导致了大量的无效数据参与了传输和运算,从而导致大量的计算资源被浪费。同时大量的算子是通过Java等高级语言写的,中间要通过虚拟机解释执行,无法充分发挥硬件的算力。
(3)大数据集群在处理数据的时候,涉及组件较多,要解决端到端的问题,各个引擎都要统一优化,优化难度特别大。
面对这些问题,鲲鹏BoostKit推出大数据OmniRuntime加速组件底座,统一支撑不同引擎,减少重复优化。OmniRuntime在数据接入阶段采用OmniData算子下推实现数据就近计算来解决难题。即通过OmniData存算协同,将数据选择率低的算子下推到存储侧,让数据在存储侧执行计算,从而实现数据的过滤,减少数据的无效搬移,让有用数据更快传输到计算层。
那么OmniData存算协同是怎么样的呢?在了解OmniData存算协同之前,我们先来了解一下传统方案的运作。
传统方案中计算是在计算节点完成的,而数据是在存储节点存储的,那么大量的数据需要从数据存储节点通过网络传输到计算节点,造成网络的瓶颈。计算效率比较低。
而通过OmniData存算协同,将包含操作、运算规则的算子卸载到边缘侧,计算在数据本地进行,降低数据的搬迁,消除网络传输的瓶颈,使得计算效率大大提升。
什么是OmniData
对于大量计算节点读取远端节点数据的大数据存算分离场景或大规模融合场景下,大量原始数据需要从存储节点通过网络传输到计算节点进行处理,有效数据占比低,极大地浪费了网络带宽。针对该业务痛点问题,我们提供了OmniData特性,能够实现近数据计算,将算子卸载到边缘侧执行,降低数据搬迁量,消除网络传输瓶颈,SQL计算性能平均提升40%。
下推是一种经典的SQL优化手段,它会尽量将一些算子推向靠近数据源的位置,以减少上层所需处理的数据量,最终达到加快查询速度的目的。OmniData特性提供的主要功能如下:
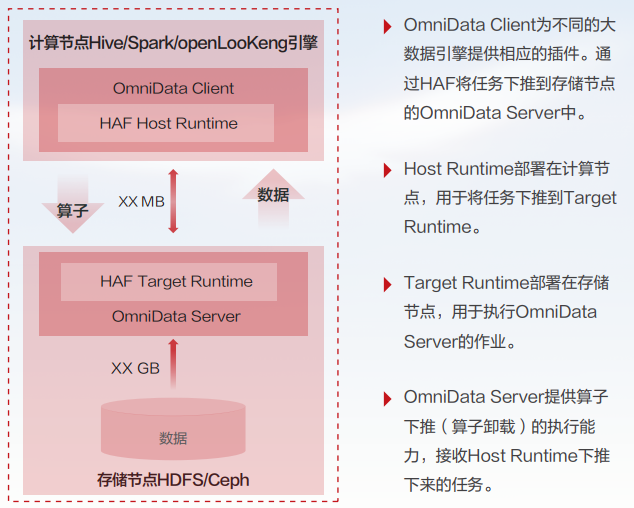
(1)实现将Hive/Spark/openLooKeng引擎计算节点的Filter、Aggregation、Limit算子下推到存储节点进行计算,将算子处理完后的结果通过网络传输到计算节点,降低网络传输数据量,提升Hive/Spark/openLooKeng引擎的计算性能。
(2)实现对接同构加速框架HAF(Homogeneous Acceleration Framework),替换原有GRPC通信下推框架的server/client接口,通过Java注解形式实现下推。
(3)实现将算子下推到Ceph/HDFS存储节点上处理。
大数据OmniData软件架构和关键业务处理过程如下图所示:
OmniData应用场景
1. 大数据存算分离或大规模存算融合场景
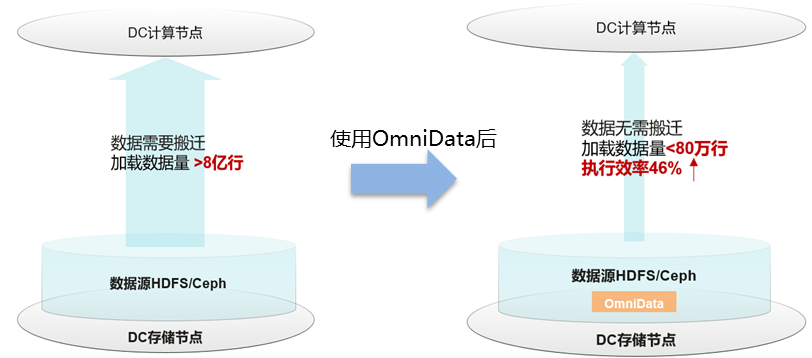
以某客户业务SQL为例,SQL含有多个过滤算子,算子需要跨网络从远端存储节点读取超过8亿行的数据;使用OmniData特性后只需要传输过滤后的有效数据80万行。具体优化过程如下:
过滤算子下推到存储节点OmniData服务中执行,数据在本地读取,过滤后的有效数据80万行通过网络传输到计算节点,极大降低了网络传输量,提升计算性能。
(1)设置下推策略:依据计算引擎对数据的统计信息,获取算子的输入/输出数据量,计算有效数据比例,在比例小于设定值时使能下推,避免过滤数据量少,收益低于下推开销,造成性能负收益。
(2)可靠性保证:存储系统提供数据的多副本存储,算子下推时会通过ZooKeeper中状态信息判断副本所在节点的OmniData服务是否正常,若有故障,则选择其他副本中的OmniData服务,若多个副本的服务均故障,则回退到原生流程,在计算侧执行。
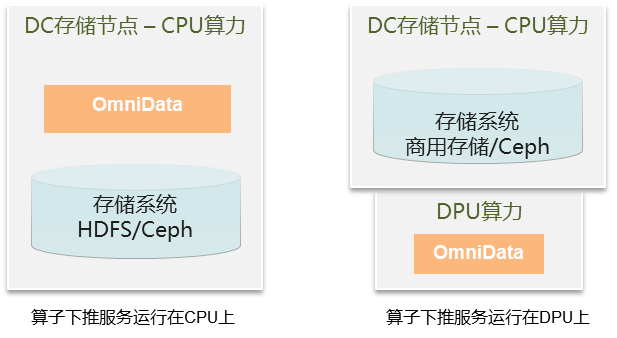
2. 开源或商业存储场景
开源存储系统例如HDFS或Ceph对CPU算力要求低,存储节点有很多空余的CPU;商用存储系统或优化后Ceph对CPU算力占用多,存储节点无空余CPU算力。
开源存储系统的节点上可以通过cgroup限定OmniData下推服务的使用资源;商用存储系统或优化后Ceph对CPU算力占用多,节点插入DPU卡,OmniData部署在DPU中,利用DPU算力实现下推。当节点资源受限时,通过自有硬件扩展算力,实现计算性能提升。