鲲鹏BoostKit干货店丨性能倍增!!“即插即用”的大数据机器学习算法
发表于 2021/07/14
0
业务场景延伸,数据量爆发式增长,使得开源大数据机器学习算法的应用场景广泛而多样。但随之也带来了更大的挑战,开源算法收敛速度慢,硬件匹配度不足,导致很多场景算不了、算不快、算得贵。
鲲鹏应用使能套件BoostKit提供基于开源算法深度优化的机器学习算法,为开发者提供极致性能的大数据分析体验。本文由华为机器学习算法专家刘康玲为你揭秘鲲鹏BoostKit如何围绕算法共性原理创新和算法鲲鹏亲和性优化,实现数据处理的倍级性能提升。
算法共性原理创新
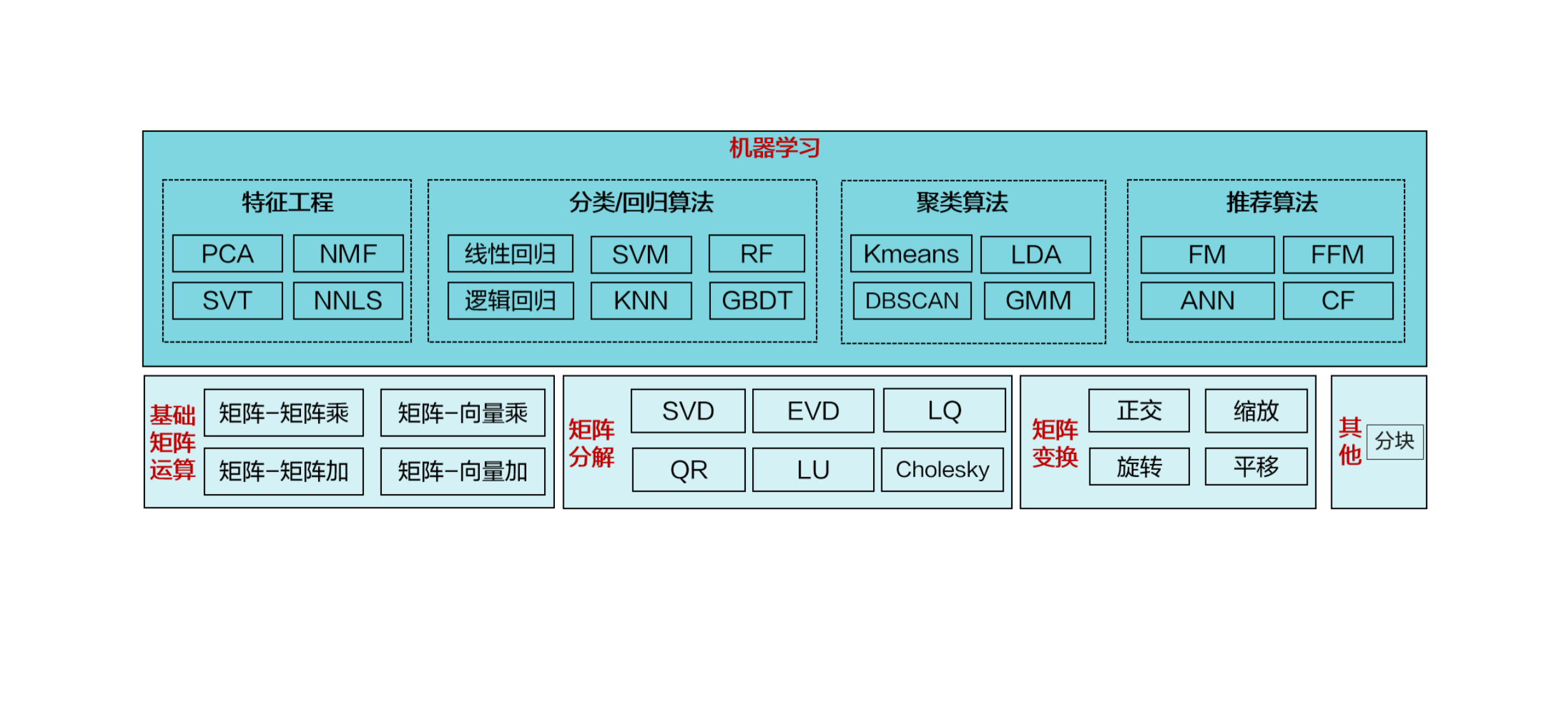
矩阵计算是机器学习算法的核心组成部分,覆盖数据输入、算法描述、算法训练等计算过程。然而,在当前开源算法中,矩阵计算通常会成为计算瓶颈。鲲鹏BoostKit针对不同数据分布和规模下的矩阵计算场景,开展共性原理创新,在同等计算精度下,实现计算性能大幅度提升。
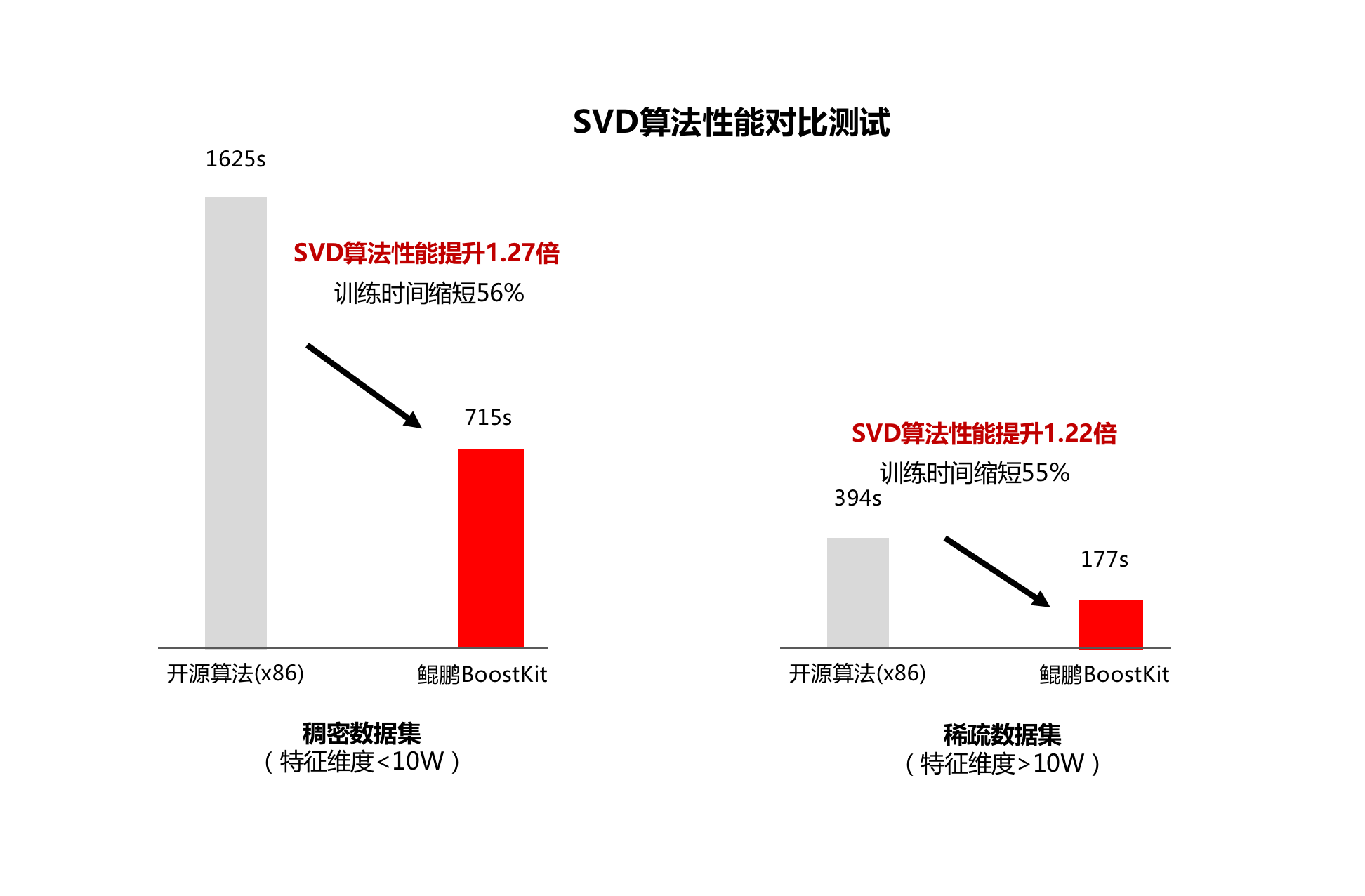
以特征降维算法PCA(Principal component analysis,主成分分析)为例,经分析99%的计算耗时在于底层调用和运行SVD(Singular value decomposition,奇异值分解)算法,如果不进行SVD算法优化,会导致个性化推荐、关键对象识别、冗余信息缩减等场景的数据分析困难。
因此,鲲鹏BoostKit通过优化重启技术、减少迭代轮次等优化手段,加快SVD算法的收敛速度,提升SVD算法对奇异值不分离和奇异值范围大,以及对高维数据场景的适应性。
在同等计算精度下,鲲鹏BoostKit的SVD算法能够将数据分析性能提升1.2倍以上。
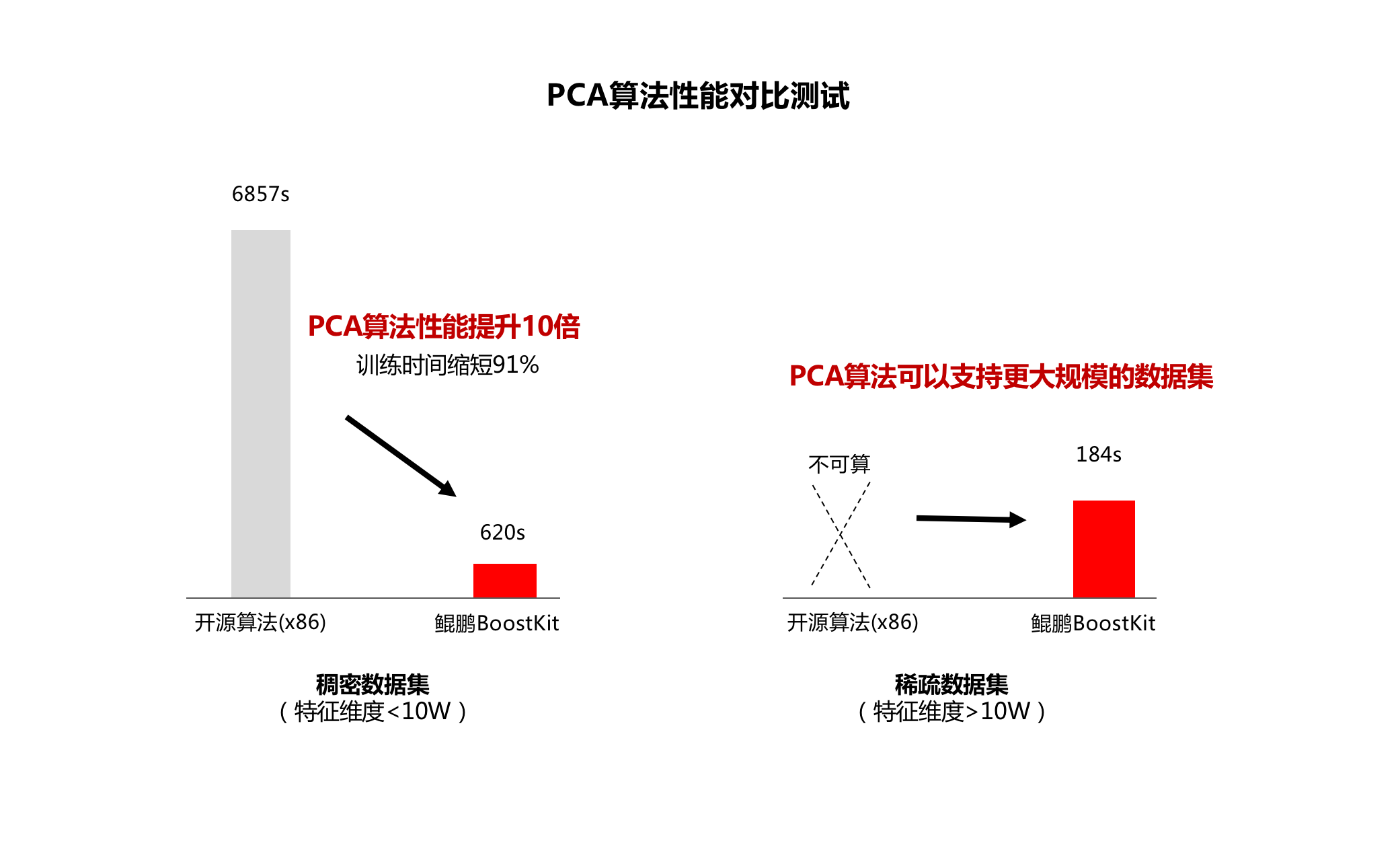
此外,鲲鹏BoostKit还对采用优化后的SVD算法选择求解最大的一些奇异值,相比开源算法的全部奇异值求解,可以显著降低PCA算法的计算量。
在同等数据集和同等计算精度下,鲲鹏BoostKit的PCA算法不仅实现10倍以上的性能提升,甚至能够使能一些开源算法无法计算的超大规模数据集场景。
鲲鹏亲和性优化
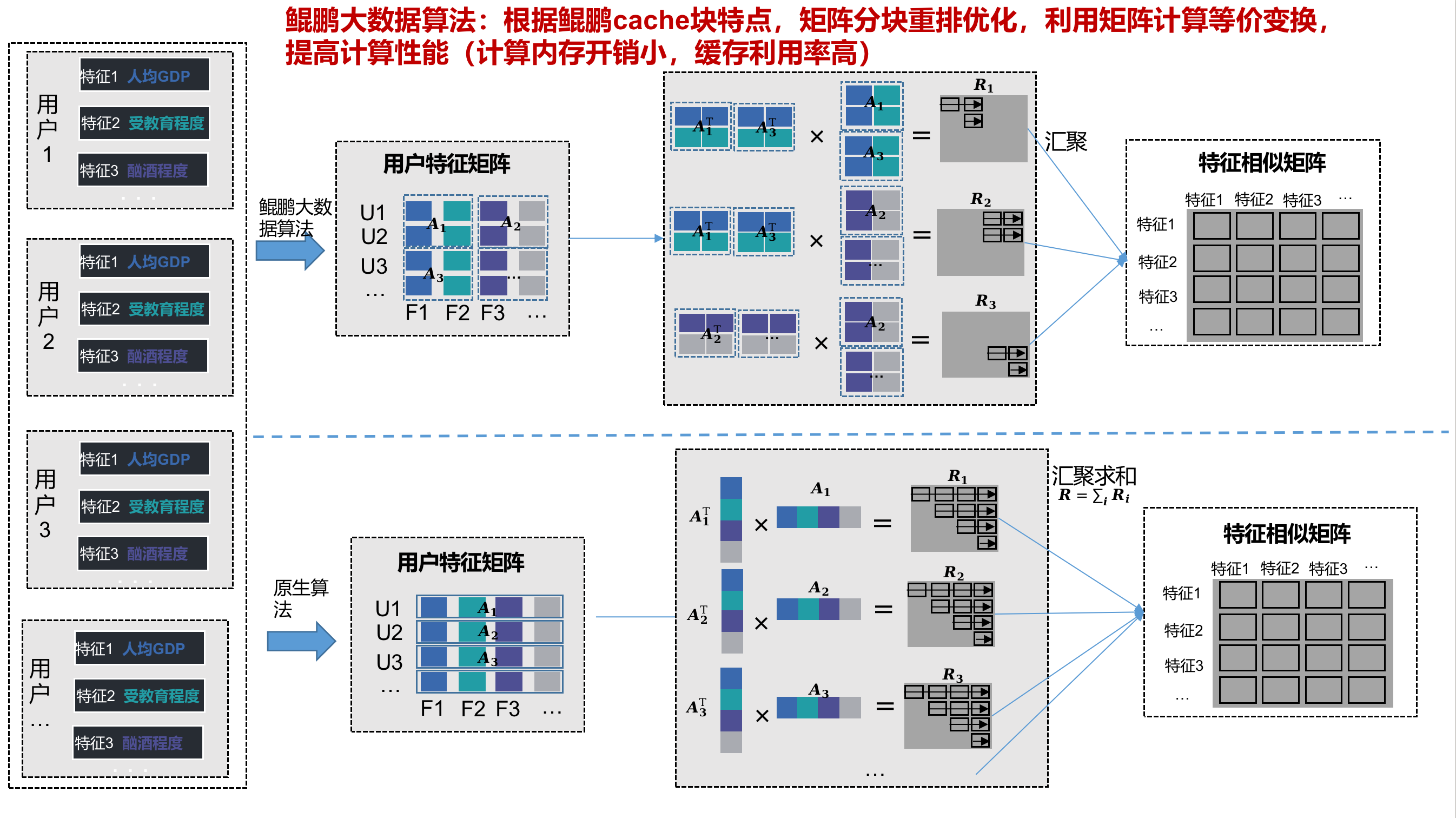
为了充分匹配和发挥鲲鹏架构的硬件优势,鲲鹏BoostKit从访存时延、多核并行等方面进行算法亲和性优化。
在访存时延优化方面,鲲鹏BoostKit充分利用鲲鹏Cache(高速缓存)块特点,通过优化矩阵分块技术,保持访存和计算的连续性,有效提升Cache命中率,降低时延。
在同等计算精度下,Covariance(协方差算法)、Pearson(皮尔逊相关系数)、Spearman(斯皮尔曼等级相关系数)等机器学习算法的性能提升超过50%以上。
在匹配鲲鹏多核能力方面,鲲鹏BoostKit通过设计并行优化方案,消除通信瓶颈,提高计算并行度,实现RF(Random Forest,随机森林)、GBDT(Gradient Boosting Decision Tree,梯度提升决策树)算法等机器学习算法性能最高提升2.5倍。
获取方式
鲲鹏BoostKit机器学习算法对接主流生态框架,保持与原生Spark算法完全一致的类和接口定义,无需上层应用做任何修改,就可平滑迁移至鲲鹏计算平台,并获得性能加速。
目前鲲鹏社区已经发布了鲲鹏BoostKit的18个机器学习和21个图分析算法,覆盖主流的大数据算法应用场景。
本页内容